Inden vi starter – bayes teori og forudsætningen: Hele bloggen forudsætter, at man kender lidt til Bayes teori
Bayes teori i akutmedicin: Præ-test sandsynlighed x LR (testens vægt) = post-test sandsynlighed
Jeg har tidligere gennemgået dette emne – senest i “brick by brick del 1”, men er man mere til video, så kig med hér, når Casey Parker (BroomeDocs) forklarer koncepterne brilliant
eller Rahul Patwari (clinical reasoning del 2-8 på youtube):
Vil du have en ikke-medicinsk video om Bayes teori (som alt det her bygger på) så er den her nok en af de bedste:
Ud fra Bayes teori får vi nogel af de gyldne regler i akutmedicin – noget vi kan kalde akutmedicinerens fadervor:
Evidence should not determine believes but update them
Patienter har ikke sygdomme, kun sandsynligheder for sygdommeVores diagnostiske tests er kun revision af sandsynligheder
Diagnostiske tests kan aldrig fortolkes uden præ-test sandsynlighedsbedømmelse
Prætest sandsynligheden afhænger af gestalt, og sygdommens forekomst i en given population
Akutmedicinsk probabilistiske fader vor bl.a fra Schecther et al, 1985: Diagnostic testing revisited: pathways through uncertainty; Reuben Strayer: Emergency Medicine Thinking (youtube)
Undgå “ready fire….aim” (test interpretation should precede test ordering)
Man udskrives altid med en post-test sandsynlighed uanset mængden af test udført
På et tidspunkt bliver post-test sandsynligheden så lav, at risk-benefit er ufavorabel for flere tests
Fly ahead of the plane: Positive tests fører os videre, negative tests afslutter. Spørg altid dig selv, hvis positiv / negativ udfaldet af en test ændrer håndteringen – hvis ikke, så lad være med at udføre den
og er man til eksempler på hvorfor PTP er så vigtigt, så et godt eksempel illustreret i
og jeg har flere eksempler i mine blogs, bl.a brick by brick del 1, hvor jeg gennemgår en hel case med alle de probabilistiske overvejelser jeg (teoretisk) har igennem et forløb.
PTP (Pre-test sandsynlighed)
Denne del 1 læses bedst med kendskab til model 1-3 i del 2 af denne blog. Man kan med fordel derfor læse disse inden man går videre, eller ser videogennemgangen herover af Casey Parker
PTP er kernen af diagnostik og er som bekendt sandsynligheden for en pågældende sygdom / tilstand, før du udfører en test, og afhænger af prævalensen af sygdommen, samt hvilken setting man er i (befolkning, almen praksis, akutmodtagelse, afdeling etc) og hvilken filterfunktion patienten har været igennem, for at komme til denne setting .
PTP bedømningen kan gøres på flere komplimenterende måder. Vi gennemgår i denne blogserie de to skoler (Naturalistic decision making- NDM Vs HB: analytisk/ heuristisk) – den kliniske erfarne tilgang (gestalt – (se del 2 model 7). PTP er altså altid en bedømmelse ud fra
- Gestalt / klinisk erfaring
- Epidemiologisk data ud fra din population (hvor hyppig er sygdommen i din population)
Du kan i princippet ikke fortolke en test uden PTP-bedømmelse, så det er helt centralt, at du kender til dette begreb indgående
Ordene vi anvender og basale koncepter
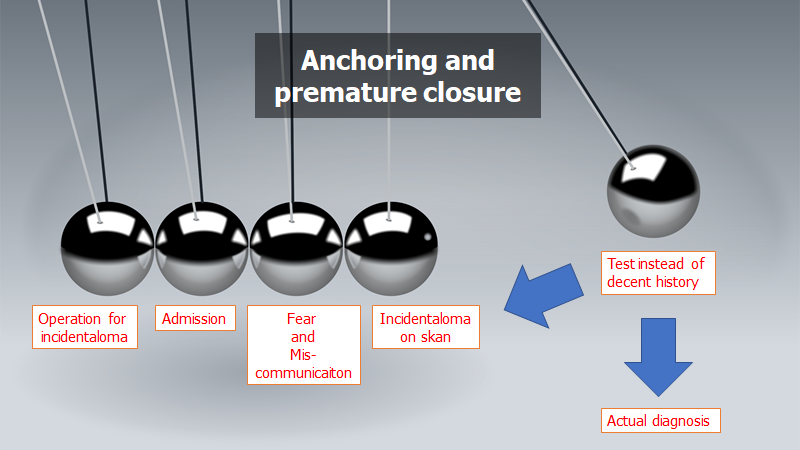
Fra udifferentieret præsentation til PTP: Man skal huske, at patienten jo ikke kommer ind med en sygdom, men med en præsentation. Derfor vil der skulle foregå en slags distillering af patientens information til nogle differentialdiagnoser, som vi gerne vil udelukke (denne process fra udifferentieret patientklage til liste med differentialdiagnoser er flydende og skal være åben hele vejen igennem, men med nogle tilstandes sandsynlighed der eventuelt stiger højt nok til at de “stikker ud”, så man gerne vil reducere deres risiko. Jeg har forsøgt at forklare denne process i brick by brick del 1, og vil henvise dertil for dybere forklaring). Kodeordet er: aktiv lytning, sid ned og undgå at afbryde patienten når de fortæller sin historie (for at undgå premature closure) (se figur herunder)
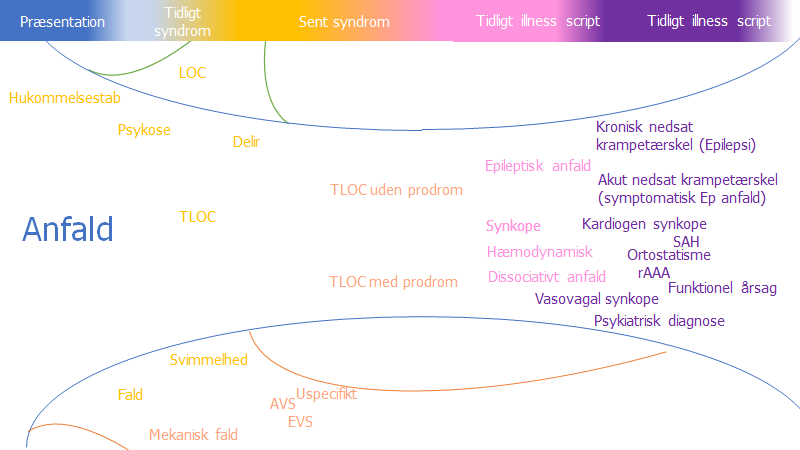
Forklaring af figur: Øverst findes en bar, der fra venstre imod højre kommer tættere og tættere på en specifik diagnose (præsentation -> syndrom -> illness script). Man bevæger sig klinisk fra venstre imod højre, ved at få data indsamlet. Ordene på figuren, er farvet, så de tilknyttes, hvor langt vi er i diagostnikken. Anfald er fx en udifferentieret præsentation, TLOC er et tidligt syndrom, da det stadig er ganske bredt, og Epileptisk anfald er et “illness script” (sygdom). Starter man for langt på højre side i sin tankeprocess, er man i stor risiko for at fejldiagnosticere patienten i akutmedicin. Fordi patienten statistisk set sjældent fejler noget farligt, er der ikke altid konsekvenser ved det, og derfor får vi ingen korrigerende feedback – se senere “bad decision -> good outcome” i del 3 af denne blog
“Boblerne” øverst og nederst i figuren (blå linjefarve) forsøger at illustrere at man kan gå andre veje når en patient kommer med et “anfald”. Disse “rabbit holes” vil man misse, hvis man starter med at tage det for gode vare, at patienten har haft et “epileptisk anfald”
Fortolkning og anvendelse klinisk: Du får måske at vide fra triagen eller ambulancepersonalet, at “patienten har krampet”. Du har det i baghovedet, at det kan være en epileptisk krampe, men du spoler båndet tilbage og starter bredere (fordi du ved, at “kramper” tilhører en større overgruppe som hedder TLOC (transient loss of consciousness), og denne tilhører en overgruppe kaldet “anfald” eller “episoder”). Denne tankeprocess som vi kan kalde en sproglig “forcing strategy” (for at undgå cognitive bias) reducerer vores risiko for, at for tidligt gå for dybt ned i et diagnostisk syndrom (for tæt på højre side af linjen). Starter man ikke fra start (“anfald” – venstre på figuren), vil man kunne gå ned i et forkert “rabbit hole”, og være i høj risiko for “framing”, “anchoring”, “diagnostic momentum” og “premature closure”
Et andet eksempel er “brystsmerter”. Tænker man ikke “smerter” fra start, kan det være, at man misser boksen med sine egne tidskritiske tilstande, der hedder abdominal smerter, rygsmerter og “smertesyndromet” og den psykosomatiske samtale med patienten.
Se fx https://first10em.com/cognitive-errors/ for detaljer om de enkelte cognitive bias, og se brick by brick del 1 for en indgående forklaring

Hvordan bedømmer vi så PTP for sygdom x for en given sygdom, når vi har taget højde for hvilken præsentation patienten sandsynligvis har? Det konkrete kliniske svar får du senere. Indtil da, er det korte svar, at PTP er dynamisk og forskellig alt efter hvor du er i den diagnostiske process. Her er nogle eksempler:
- Inden du ved noget om patienten, og du står ude i befolkningen: PTP er baggrundsprævalensen for sygdom x
- Når du ser patienten, men ikke ved andet om ham/hende i fx akutmodtagelsen: PTP er prævalensen for sygdom x på din akutmodtagelse. Disse data findes aldrig (…endnu), og det er derfor et overslag, som bl.a afhænger af studier fra sammenlignelige akutmodtagelser og systemer om sygdom x (fx ved vi, at SAH på svenske akutmodtagelser er ca 10% af dem, der kommer med thunderclap headache). Dette tal varierer fra system til system (nationalt og internationalt), alt efter “patientens vej” til akutmodtagelsen (se filter / triage senere). Optimalt kender du til et slags mål for vores potentielle under- eller overdiagnostik af et problem, således at vi kender den sande POEM-værdi (patient oriented outcome that matters) ved sygdom x. Tager vi AKS som eksempel, er vi ikke så interesserede i, at kende til prævalensen af AKS patienter på akutmodtagelsen, der modtager revaskularisering som mål, men dem, der får skader (fx hjertesvigt) og dør. Vi leder ikke efter diagnoser på en akutmodtagelse. Vi forsøger at reducere patientens risiko for tidskritiske outcomes – og vi skal være opmærksomme på, at de “kasser” vi kalder diagnoser sjældent entydigt har dårlige outcomes eller er skarpt definerede enheder ud fra POEM.
- Når du begynder at vide mere om patientens demografi på akutmodtagelsen: sygdom x’ forekomst i denne demografiske gruppe på akutmodtagelsen (fx ældre med brystsmerter)
- Når du begynder at “teste” (for detaljer se “brick by brick del 1”): tests er alt fra “gestalt” (helhedsindtryk / mønstergenkendelse ud fra summen af dig bevidste- og underbevidste elementer af patientbedømmelsen); kommunikationsteknik- og evne / anamneseoptags evne; Objektiv undersøgelse; Parakliniske tests. Før testen udføres er PTP én værdi, og afhængigt af testens styrke (sensitivitet, specificitet, LR+/- – se senere), og hvor meget vi kan stole på den (Falsk positiv rate, falsk negativ rate, inter-rater reliability), vil testen være i stand til at ændre PTP til en post-test sandsynlighed. Denne Post-test sandsynlighed efter test 1, vil blive til den nye PTP inden du udfører test 2.
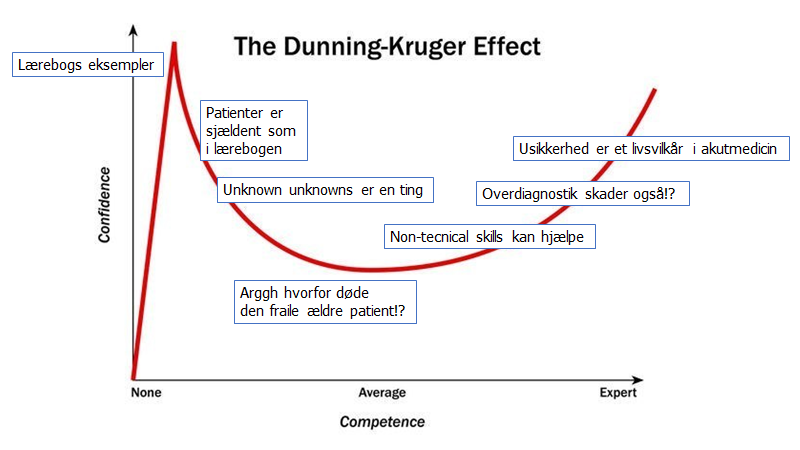
Balancen mellem ydmyghed og selvsikkerhed: I bedømmelsen af PTP ligger også konceptet “unknown unknowns” / Dunning-Kruger effekt. I starten af vores karrierer eller første gang vi møder noget, er vi meget bevidste om, at vi ikke ved noget (known unknowns). Men efter at have arbejdet med det i kort tid, får vi en følelse af, at vi kan det – ofte er dette fordi vores gestalt og system 1 overrider vores analytiske tankemåde (system 2). Man er i dette moment i “blindspot-bias’” vold – vi ser ikke det, der er galt (unknown unknowns).
Den eneste måde man kan komme ud over dettte tidlige punkt med høj selvsikkerhed, men lav kompetence, er ved at være åben overfor feedback. Åbenheden overfor feedback og det mindset man skal have, kalder jeg “spotting the right“, efter inspiration fra St emlyns blogs om feedback, og i som modstætning til “spotting the wrong“. Spotting the wrong er en slags emotionel drevet refleks-lignende forsvarsmekanisme vi – uden øvelse i at modtage feedback – ofte ubevidst ender i. Spotting the wrong leder sjædent noget konstruktivt med sig, og kunsten er , at blive det bevidst, og efter den “emotionelle reaktion” på feedback, reflektere over hvad feedbackens indhold var (spørg gerne ind til detaljer, så man faktisk forstår feedbacken). For detaljer, se
- St emlyns Feedback blogs
- Min blog om feedback (kommunikation del 3)
- Thanks for the feedback-bogen af Heen og Stone (se også video herunder og i kommunikation del 3)
Blomsten, der er feedback, behøver et godt miljø for at kunne vokse: For at sikker feedback kan forekomme i et system, behøver man på alle nivauer af systemet (igen – ALLE niveauer: politikere, sygehusadministration, afdelingsledelse, iblandt læger, iblandt studerende på studiet, iblandt mennekser generelt) at frem-elske det, jeg kalder “safe-container”-princippet (udvidet koncept lånt fra en artikel om simulationstræning af Rudolph et al, 2014: Establishing a Safe Container for Learning in Simulation). Safe containter fordi det i en kaotisk hospitalsverden skal være barmhjertigt at forklare om de hændelser der er sket – uden at man skal anklages for det, føle sig “dum” eller “bange” for at forklare om det. For at folk tør kigge på dem selv i et barmhjertigt og selv-reflekterende lys, skal miljøet ikke være toksisk. Hverken det
- Medico-legale system tryk: Bliver jeg anklaget, hvis jeg kommer frem og siger, jeg har lavet fejl?
- Det lægevidenskabelige systems tryk: Er fejl acceptable indenfor vores kultur som læger? Tror vi stadig vi er perfekte som fag?
- Det afdelingsmæssige tryk: Findes der en kultur på afdelingen, hvor overlæger- som yngre læger kan gå frem, hvis de føler, at de har lavet fejl, og prospektivt gå igennem cases? Anvendes i stedet “retrospektroskopet” ved alle cases i en slags “hvorfor gjorde du ikke xx og yy – det var da let at se!”. Er man bevidst om konceptet om Dunning-Kruger effekten er uafhængig af rang (overlæger som yngre læger er udsat for den!) og deraf vigtigheden af åbenhed omkring feedback?
- Det personlige tryk: Tænker folk i smug, bag din ryg stadig at de ville have gjort det anderledes, og tror ikke, at din case er gældende for dem? Anses du som en dårligere læge, hvis du er bevidst om dine mangler?

Andre basale principper i probabilistisk tankegang: Der er nogle principper tilknyttet PTP som også er relevante for kommende diskussion:
- Tærsklen (threshold – se tærskelmodellen herunder): Er patientens præ-test sandsynlighed over en test-tærskel, bedømmes det relevant at udføre testen for at reducere patientens post-test sandsynlighed. Er patientens præ-test sandsynlighed under tærsklen for test (det være sig anamnestisk udspørgen, objektiv undersøgelse, blodprøve, EKG eller enhver anden test), vil testen enten være ufortolkbar eller være i høj risiko for at skabe falsk positive.
- Testen: Udførelse af en test er aldrig diagnostisk i sig selv, men ændrer blot på præ-test sandsynligheden og giver os en post-test sandsynlighed (sandsynligheden for sygdom x (og også y og z) efter testen er udført, i fald den fortolkes sand negativ / sand positiv. Mængden af ændringen afhænger af testens evne (kan udtrykkes som Sensitivitet / specificitet, men mere klinisk relevant som Likelihood ratios), og om testen udføres korrekt og er reproducerbar (interraterreliability – IRR). Tests der er svære at få feedback på (fx lungeauskultation), særligt hvis de er teknisk svære eller kræver stor erfaring (fx at høre “third heart sound”), vil have en dårlig IRR. Vi er selv en test (gestalt), og vores kommunikationsevner kan være en god eller en dårlig test, alt efter hvor gode vi er til fx klinisk spørgeteknik og aktiv lytning.
Mange tests har høj LR, men er lav-sensitive og høj-specifikke og med dårlig IRR, og er derfor for praktiske formål næsten uanvendelige: Et godt eksempel er third heart sound for hjertesvigt (LR+ 57 på theNNT), men en k-værdi (IRR) mellem -0,17-0,84 (Steve McGee 2017). En god LR er med andre ord ikke lig med en test, man altid skal anvende (kig også på sensitiviteten og specificiteten)
Vores viden om tests kommer fra studier: Den population som testen er udført i, formålet med testen (giver den mening og er den realistisk?), hvem der har udført testen i studierne m.m er derfor vigtigt. En test for rheumatoid arthrit (fx RF-blodprøven), klarer sig væsentligt bedre i en population af højrisiko patienter, end på almen praksis niveau. - Testen uden præ-test sandsynlighed: Får du et EKG i hånden uden at kende til præ-test sandsynligheden, kan du aldrig udtale dig om det er normalt. En test kan aldrig fortolkes uden stillingstagen til præ-test sandsynligheden
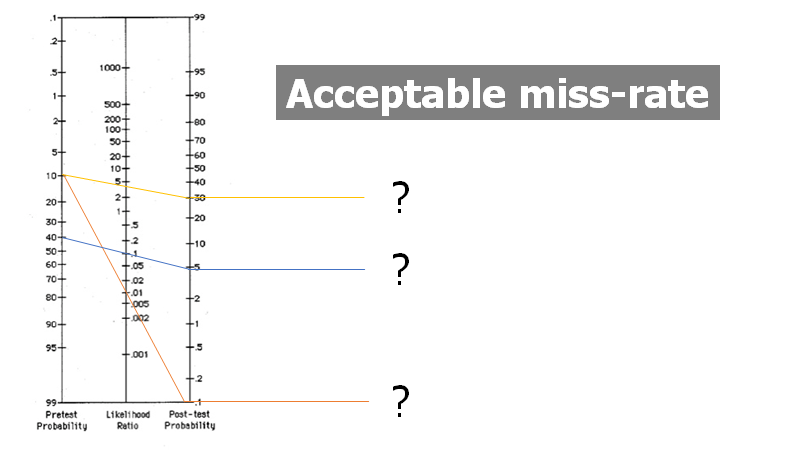
- Post-test sandsynligheden: Patienter har ikke diagnoser, men kun sandsynligheder for diagnoser, og vil således altid udskrives med en post-test sandsynlighed, uanset hvor meget du udreder dem. Hvor vores “acceptabel miss-rate” (hvor mange vi vil misse – 1/40, 1/100, 1/1000?) er ligger, er en balance imellem
- a) alvorligheden af sygdommen, samfundets (og individets) mening om konsekvenserne ved at misse denne sygdom; vores tests evne til at finde sygdommen, og konsekvenserne / komplikationerne ved disse tests. Desuden er det ultimativt også vigtigt, om vi har en behandling. Strokes var tidligere mere acceptable at misse, da der ikke fandtes en særlig behandling for dem. Desuden (desværre) også det medico-legale klima og risk proximity , der generelt leder til b (herunder). Bemærk desuden, at befolkningen som helhed, ikke nødvendigvis er rationelle omkring deres forventning
- b) Risikoen for overdiagnostik og falsk positive, psykologisk stress, somatisering og fortsat lidelse for patienten ved “fokusere på det forkerte” (fx fokusere på biologisk komponent, når den psyko-sociale komponent ikke er blevet addresseret)



Epidemiologisk data og PTP: Kend din population og filter
Den population jeg ser på et Stockholms akutmedicinsk afdeling er ikke det samme, som jeg så, da jeg var på akutmodtagelsen i Jylland (I Stockholm er den betydeligt raskere). Og på akutmodtagelsen i København, var det heller ikke som i Jylland. Hvorfor er det sådan?
Det vil jeg prøve kort at løbe igennem i denne del.
Det kan virke tørt, men det er formentligt en af de vigtigste ting at kende til som læge på akutmodtagelsen!
Jeg kan ikke nå igennem alle detaljer af dette emner, men fokuserer på
- Filterfunktionen
- Geografi og Demografi
- Mikropopulationer
Så populationen du ser på akutmodtagelsen afhænger af:
1. Sygehussystemets filter / gate-keeperfunktion / triage
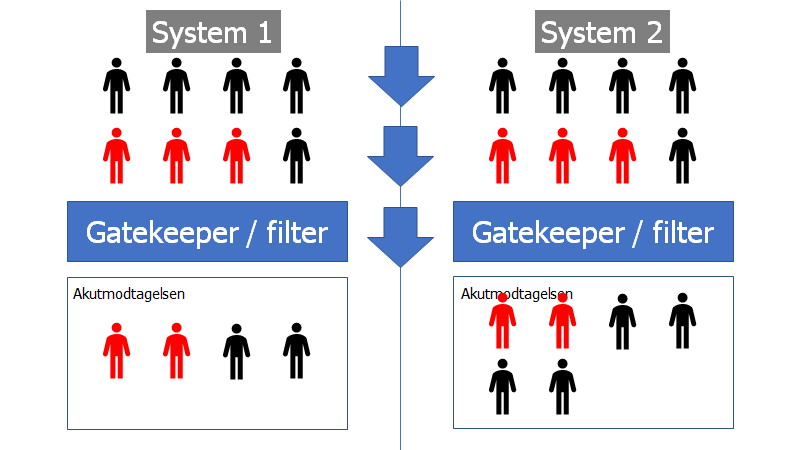
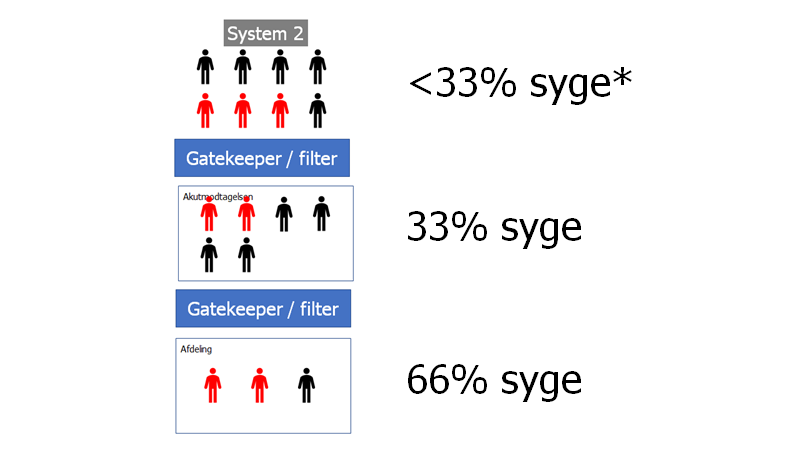
I system 2 (til højre), har man valgt at prioritere sensitivitet, på bekostning af specificitet. Modellen er for lille til at vise det, men i princippet vil meget få røde personer misses af filteret på bekostning af, at enormt mange flere sorte kommer ind
Bemærk, at overstående model ikke tager højde for, at patienter med alvorlige sygdomme ofte ringer igen / kan komme tilbage – det afhænger af hvilken information de får
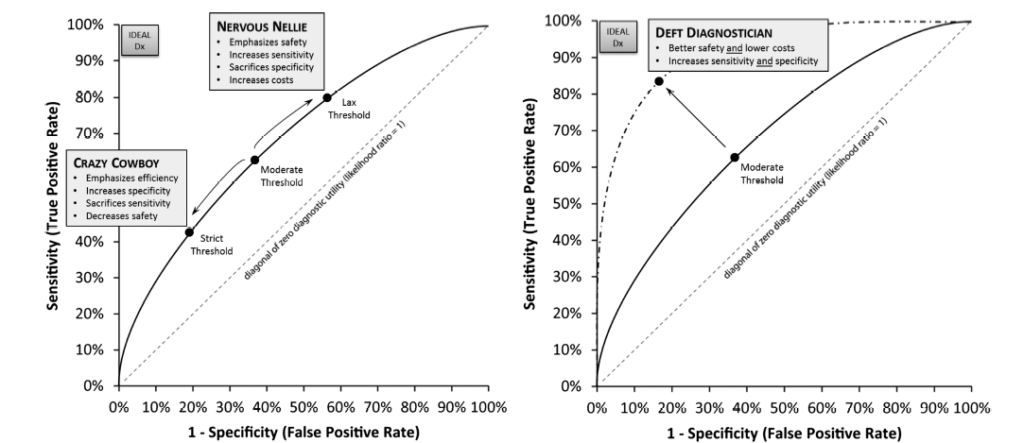
Overstående figur, er en anden fremstilling af problemet og købet mellem et triagesysatem / filtersystem der prioriterer enten specificitet eller sensitivitet. Optimalt set, vil vi have en system, der er optimalt mellem begge verdner (“deft diagnostician”)
Overstående figurer er ikke lavet ud fra systemer, men ud fra individer (læger)
Tænk dig, du er en patient og føler dig dårlig nok til at behøve at søge læge (tærskel for at søge læge): I forskellige sundhedssystemer vil der være forskellige “filterfunktioner” inden patienten ser dig som akutmedicinsk læge. Filteret (som kan bestå af flere led) kan tænkes som en test med sensitivitet og specificitet, og systemet designer (bevidst eller ubevidst) sine filtre, alt efter hvad målet er:
- Nogle filtre prioriterer en høj sensitivitet, oftest på bekostning af en lav specificitet (send alle ind, mis ingen!) – dette er fx telefonvisitation- og telemedicinske løsninger (system 2 herover).
- Andre systemer (fx almen praksis læge triage og lægevagtsordninger) har et stærkere filter, således at den population der kommer til dig er sygere, men kan misse lidt flere – men vil generelt være en bedre og mere relevant håndtering af vores ressorucer (deft diagnostician og system 1)
Dette er altså altid et tradeoff uanset hvad – heldigvis dør de fleste patienter ikke ved en forkert visitation. De ringer / søger når det bliver værre. Vi bevæger os dog i højere og højere grad imod et system, hvor alt skal løses i første forsøg (hvilket er umuligt ud fra de uperfekte tests vi har i til rådighed). En forklaring bedre, end jeg kan forklare det, er lavet af Raul Pathwari
I nogle sundhedssystemer kan man tænke, at patienterne “høstes” til at søge læge (gennem mediekampagner, telemedicinsk tilgængelighed m.m). Vi kan altid undre, om denne “høst” af potentielle patienter giver en sundhedsfordel, eller blot sygeliggør / somatiserer vores patienter
2. Lokale og demografiske forhold
(bemærk: sygdom og lidelse er to forskellige ting – de kan overlappe, men er ofte to forskellige ting jf psykosomatiske tilstande, som også skal tages ligeså alvorligt som somatiske tilstande)
Dette har noget at gøre med hvordan populationen fra start – før filterfunktionen – er i basissundhed, og hvilke sygdomme som prævalent findes i populationen (fx pga geografi, genetik etc)
Forestil dig, at du i morgen flytter til en akutmodtagelse i Pretoria, Sydafrika. Selvom du sikkert vil kunne bruge en stor del din kliniske erfaring og viden, så kan den ikke direkte appliceres, fordi populationen er anderledes af flere grunde: anden demografi, anden kultur og søgemønster, andet design og adgang til sundhedssystem, andet medico-legalt klima m.m
Case: Din næste patient er en 30 årig mand med svære mavesmerter, som ikke kan finde ro
Hvilke “don’t miss” diagnoser går gennem dit hoved på akutmodtagelsen i Danmark?
Hvad tænker de i Sydafrika?
3. Mikropopulationer
Du behøver ikke at skifte land for at opleve forskellige populationer. En anden – måske tydeligere – populationsforskel kan være mellem by- og land, og i subpopulationer i den enkelte storby. Arbejder du på BBH (bispebjerg hospital) og har en stor population af psykatriske patienter og misbrugere. Arbejder du derimod på Nordsjællands hospital, i Gentofte eller på et jysk hospital fx Åbenrå, ser du en helt anden population. Men relativt små geografiske forskellige kan ændre din population. Jeg arbejder på et hospital, som geografimæssigt svarer til Gentofte. Men fordi vi har Stockholms største misbrugscenter og psykiatri ved siden af, blandes populationen, og ser derfor mere ud som en Herlev population (blanding af gentofte- og nordvest optageområdet). Det er derfor vigtigt at kende til mikro-populationerne du arbejder med – uanset hvor du arbejder, og kende dit lokalområde og vejen / filteret for patienten ind til dig

De klager begge over brystsmerter
Mikropopulationer kommer til dig
Husk også, at mikropopulationer også kan komme til dig. Arbejder du på et sygehus med høj forekomst af turisme? (fx Hjørring). For os alle kan Sydafrika komme til os gennem international turisme. Din feberpatient er pludselig ikke så standard, hvis han er fra Indien og har leget med aber i de seneste 6 måneder.
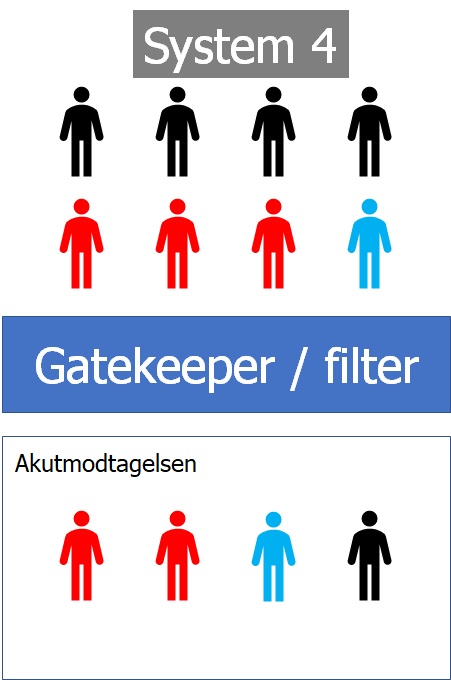
Sygeligheden (acuity) af din population ændrer sig alt efter hvor i systemet du er
When I meet a critically ill patient who is young, fit and has no other medical issue, heart failure is a very unlikely cause of their decline. However, in the ICU, we admit the sickest of patients, which results in a skewed distribution of disease. Walk around my unit today and you would be forgiven for thinking that brain bleeds, severe tuberculosis, leukemia and patients with kidney transplants are common. They are not, but when they occur, these patients often come to us. We don’t see the masses who visits their family doctor with treatable conditions that get better. We see the one person out of a thousand who has a serious rare problem that doesn’t go away without treatment. We hear hooves in the distance and expect zebras, not horses
Matt Morgan (anesthesiologist), 2018: Critical – Science and stories from the brink of human life
**tallene er ikke fra statistik, men opfundne; det er ikke de akkurate cifre der er vigtige, men tendensen der forsøges afbilledes – tallene afbilleder behandlingskrævende sygdom
Meningenen er, at acuity / sygdomsprævalens stiger jo flere filterfunktioner de går igennem.
Det er ikke svær at forestille, at en læge fra “afdeling” vil se sygdom overalt (base-rate neglect), hvis man satte dem på en af de to andre foregående niveauer (patienter på alle nivauer klager alle over samme præsentationer fx hovedpine)
Er du vant til at sidde “sent” i den diagnostiske vej for patienten, kan det nok betale sig bedre for dig at bestille en masse test (da du ser en sygere population). Derimod vil det være ødelæggende for hele sundhedssystemet, hvis egen læge (lav acuity population) sendte alle med feber ind til blodprøvetagning. Som udgangspunkt, så overbehandler / overtriagerer / overdiagnosticerer læger længere oppe fremme i den diagnostiske vej (husets speciallæger), og tidligere i systemet underdiagnosticerer (men har tricks til at undgå det – se “time as a test” og “shared decision making” senere)
Jeg har tidligere talt om “mønstergenkendelse” eller “gestalt” . Vi kan ikke arbejde uden den – men overstående viser, at vores gestalt fra et område kan lure os, hvis vi ikke tænker os om – særligt når vi har en “turist-population”, eller vi har flyttet setting. Forestil dig hjertespecialistlægen fra rigshospitalet der skal ned og triagere på en akutmodtagelse eller i 1813. Eller KBU lægen, der lige har været på sygehus, og nu skal i almen praksis og ser sygdom overalt.
Vi skal altså være mindfulle om hvilken setting vi befinder os i, og hvor syg vores population er. Det kan man ikke fuldt læse sig til, men er erfaringsbaseret og afhænger af, at man kender sin lokale population.
Som vi netop har (gen)lært, så er den test (målt ved likelihood ratio) vi vælger at anvende (hvadend det er kommunikation, objektiv undersøgelse eller parakliniske undersgelser), fuldt afhængig af præ-test sandsynligheden. Som vi nu også har lært, så er vores præ-test sandsynlighed relateret til sygdomsprævalensen i den population vi arbejder med
PTP og population – et kort eksempel
Når vi arbejder i akutmodtagelsen, tænker vi ofte ikke bare på den individuelle patient, men på grupper af patienter (utilitaristisk). Derfor kan man illustrere en tests evne til at ændre sandsynligheder, mere som at vi rykker patienten op og ned i forskellige populationer:
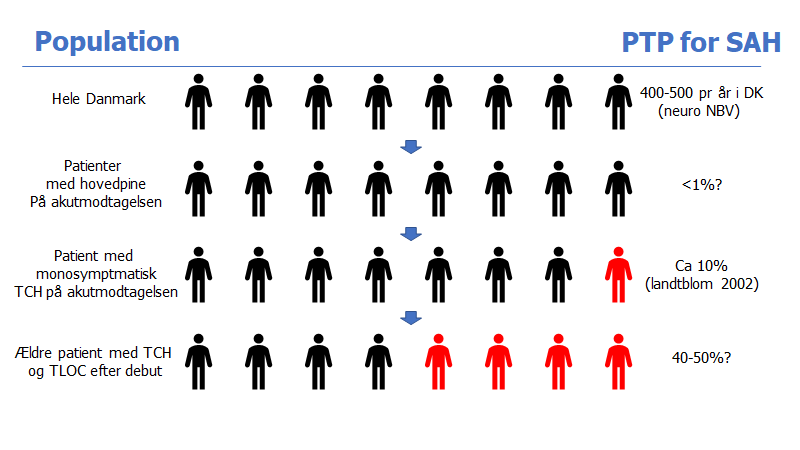
PTP: præ-test sandsynlighed, SAH: Subarachnoidal blødning, TCH: Thunderclap headache, TLOC: Transient Loss Of Consciousness
Vi plejer at tænke diagnostik, ud fra den enkelte patient – hvor sandsynligt er det, at de har sygdom x eller y med denne præsentation? Og det er godt! Men ud fra bayes teori ved vi nu, at det også er essentielt at vurdere PTP for at kunne svare på det spørgsmål. Som en vigtig del af PTP vurderingen, må vi overveje hvilken population patienten kommer fra.
- Lav risiko populationer: almen praksis patienter (dvs ikke henvist / ikke været igennem et filter); unge patienter fra en sund population uden komorbiditeter
- Høj(ere) risiko populationer: lægefiltrerede patienter (dvs henvist); ældre patienter, fraile patienter
I tv-serien, futurama findes en lidt lignende analogi. I futurama fungerer rumskibet ikke ved at brændstoffet får skibet til at flyve i relation til rummet. Skibet skubber rummet, men står selv helt stille
“I understand how the engines work now. It came to me in a dream. The engines don’t move the ship at all. The ship stays where it is and the engines move the universe around it.”
Cubert Farnsworth, Futurama – kilde: https://futurama.fandom.com/wiki/Dark_matter_engine
Når vi (også) ser patienten som en del af en population, bliver det lettere at forstå, hvorfor overdiagnostik og overbehandling kan medføre store skader. Det bliver lettere at forstå, hvorfor en acceptabel miss-rate (fx hvor mange AKS’er er det ok at misse? Hvor langt skal post-test sandsynligheden ned, før vi bedømmer denne diagnose “udelukket”) er vigtig, og grænsen for hvor vi sætter en acceptabel miss-rate skal ses i relation til NNH (number needed to harm) ved de diagnostiske tests?
Testen: Hvorfor anvender vi likelihood ratios (LR)?
Al vores erfaring, al vores analytiske tankegang, alle vores tests og al vores bedømmelse af præ-test sandsynlighed afhænger af den setting du er i og den population du arbejder med.
Testen du anvender afhænger af populationen den er testet i: En test, der har en høj sensitivitet og specificitet når testet i én population, er måske ubrugelig i en anden. Som udgangspunkt har vi lært, at sensitivitet og specificitet er uafhængige af prævalensen, og det kun er PPV og NPV, samt LR (likelihood ratios) der er afhængige. Men er det studie, hvor vi har sensitiviteten og specificiteten fra, biased og ikke generaliserbart til vores population.
These sometimes extreme differences between the population tested and the population in which the test is to be used lead to issues with generalizing results and, more importantly, yield incorrect sensitivity and specificity estimates for the test
Strassle et al, 2012: Assessing Sensitivity and Specificity in New Diagnostic Tests: The Importance and Challenges of Study Populations
Vi skal altså være skeptiske overfor hvor vi har data fra (en af grundende til, at nationale guidelines ikke umiddelbart kan anvendes i akutmedicin populationen uden kritisk stillingstagning til hvilken population de har deres data fra – som vi skal diskutere senere, så er lande vi tror er sammenlignelige fx Sverige; ikke sammenlignelige som vi tror)
For at runde dette emne af, så kan vi lige kort repetere, hvorfor sensitivitet og specificitet ikke er gode at anvende klinisk. Tag dette eksempel fra en meget anbefalingsværdig artikel: Schecter et al 1985 – Diagnostic testing revisited: pathways through uncertainty. Følgende er tre forskellige tests – hvilke er anvendelige?

Det er svært ikke?
Har du statistisk snille (hvilket jeg ikke kan prale af), vil du måske kunne komme frem til et svar som også findes på EmCrit / PulmCrit: PulmCrit – Mythbusting sensitivity and specificity
Du synes måske, at vi i stedet skal anvende NPV eller PPV – og det er en forbedring, men som John Gallagher argumenterer, så er likelihood ratios det bedste af begge verdner, hvis man bedømmer præ-test sandsynligheden:
Sensitivity and specificity, including a summary display of their reciprocal relationship as a receiver operating characteristics curve, are relatively stable test characteristics [jævnfør dog studie-generaliserbarheds argumentet herover]. Unfortunately, they represent an inversion of customary clinical logic and fail to tell us precisely what we wish to know. Predictive values, on the other hand, provide us with the requisite information but—because they are vulnerable to variation in disease prevalence—are numerically unstable. Likelihood ratios (LRs), in contrast, combine the stability of sensitivity and specificity to provide an omnibus index of test performance far more useful than its constituent parts. Application of Bayes’ theorem to LRs produces the following summary equation: Clinically estimated pretest odds of disease´LR=Posttest odds of disease
Gallagher, J, 1997: Clinical Utility of Likelihood Ratios
Tager vi vores eksempel fra før, så vil jeg umiddelbart ved at kende til præ-test sandsynligheden, være i stand til at vide hvilke tests der er brugbare og til hvilket formål

Det er nu tydeligt, at test 1 og 2 er fuldstændigt ubrugelige (men vær ærlig – hvor mange troede egentlig det?)
Vil du gå endnu dybere, anbefales pulmcrits fantastiske blogserie – men vær klar til ikke at se på en D-dimer (eller nogen anden test for den sags skyld) på samme måde igen

Måden vi fortolker studier på bør baseres på bayes teori. Fragility indexet er måske en af de mest mindblowing interesante nye koncepter, jeg fandt i 2019. Tjek beskrivelsen ud via LITFL: https://litfl.com/fragility-index/
Kilder (og stærkt anbefalet læsning) om sensitivitet og LR og klinisk anvendelse af disse parametre
- EmCrit / PulmCrit, 2017 – Mythbusting sensitivity and specificity
- Gallagher, J, 1997: Clinical Utility of Likelihood Ratios
- Schecter et al 1985: Diagnostic testing revisited: pathways through uncertainty
- Strassle et al, 2012: Assessing Sensitivity and Specificity in New Diagnostic Tests: The Importance and Challenges of Study Populations
- LITFL, 2019: https://litfl.com/fragility-index/
Bringing it home: Præ-test sandsynlighed i klinisk praksis
PTP vurderingen er en blanding mellem gestalt og analytisk tankegang
- Gestalt / mavefornemmelse / erfaring
- Kendskab til klinisk epidemiologi om sygdomme i den population din patient tilhører
- Kendskab til dit “filter” / sundhedssystem og designet af det (hvordan er patientens vej til dig? – hvilken population tilhører de?)
Så mit bedste råd til vurdering af præ-testsandsynlighed og komfortabilitet med tærskler – det bedste fra system 1 og system 2, og bio-psyko-social modellen:
- Start et åbent spørgsmål og lyt aktivt uden at afbryde patienten. Patienten stopper af sig selv indenfor 1-4 minutter – stil derefter specifikke spørgsmål
- Opøv din gestalt: Få erfaring (se mange patienter), og få feedback så du kalibreres (practise doesn’t make perfect – perfect practise makes perfect). Brug dine sanser, og kig på patienten – ikke bare på monitoren (jf øvelse fra Simon carley: can we teach clinical judgement)
- Safe container: skab et sundt feedback miljø omkring dig, og i det system du arbejder i – sådan lærer vi, og bliver eksperter
- Vær opmærksom på sproget du anvender, og anvend forcing strategier til at undgå premature closure (for dig og den næste læge i rækken – diagnostic momentum)
- Start fra starten når du øver: Øv at tale om decision making i klinkken og med dine kollegaer. Fokuser ikke kun på resultatet, men vejen dertil! Spørg ikke altid kun om “er der nogen, der har en spændende case?” (det ofte zebraer), når man skal præsentere en case. Zebraer starter aldrig som zebraer. De starter med “32 årig mand kommer ind på akutmodtagelsen med hovedpine”. Få tilhørerne til at tænke selv, og argumentere for- og imod (jf fx dansk pædiatrisk selskabs case opbygning “dagens case”)
- Outcomes and judgement: Du kan få dårlige outcome af gode beslutninger. Du kan få gode outcomes af dårlige beslutninger. Vi er ofte “heldige” fordi generelt er farlige tilstande sjældne.
- Kend til illness scripts (klassiske og atypiske præsentationer,samt hvilke tests der har særligt stærke LR+/- og IRR) – men husk de er afhængige af de studier de kommer fra. Det skal altid “anpasses” til dine forhold på din akutmodtagelse
- Kend til klinisk epidemiologi: kend til incidensen for illness scripts / sygdomme – for at undgå base-rate neglect
- Hvilken population tilhører patienten?: Overvej altid, hvilken population din patient tilhører (demografi), og hvad deres risiko er ud fra dette.
- Er patienten filtreret eller ufiltreret?: Overvej hvordan “patientens vej” til dig har været (hvilket filter har patienten været igennem: visiteret via egen læge eller selv kommet ind på en skadestue efter arbejde?)
- Kend til tærskel-modellen (hjælper ikke med præ-test sandsynligheden, men hjælper med beslutninger) – jf fx denne artikel (sundblom og Dryver et al) og denne (gallagher et al 1997) og denne (Pauker et al, 1980)
- Anvend bio-psyko-social modellen for din patients bedste og for at sænke risikoen for overmedikalisering og overdiagnostik – opøv din evne i kommunikation og forståelse af tilstande der giver svære symptomer trods ingen skade på kroppen. Opøv evne til validering uanset årsag til lidelse, komfortabilitet med “ikke at fikse patientens problem” (Bent falk).
- Kend til koncepter som “acceptable miss rate” og “deliberate clinical inertia” (Keijzers 2018), “time as a test“, og “regression to the mean“, samt forskellen mellem kausalitet og korrelation
Vi skal i del 2 se på, hvordan vi kan forstå kliniske beslutninger bedre og anvende PTP kliniske situationer

Pingback: Lungeemboli Del 2 – Wells Score – DKakut
Pingback: Lungeemboli Del 3 – rGeneva Score – DKakut
Pingback: Lungeemboli del 4 – PERC Score – DKakut