1. Research
Evidens hieraki pyramiden
EBM Answer: It all depends.
Things take place in a context, often on a spectrum and rarely is there a simple dichotomized answer
Ken Milne / Andrew Worster – SGEM Xtra: How to Think, Not What to Think , og SGEM Xtra: Andrew Worster – Legend of Emergency Medicine
Evidensen i EBM præsenteres ofte i en hierakisk model formet som en pyramide med Expert oppinion i bunden, og i toppen metaanalyser (ikke at forveklse med 6S modellen, som er en anbefaling til hvordan man lettest opnår viden indenfor et nyt felt).
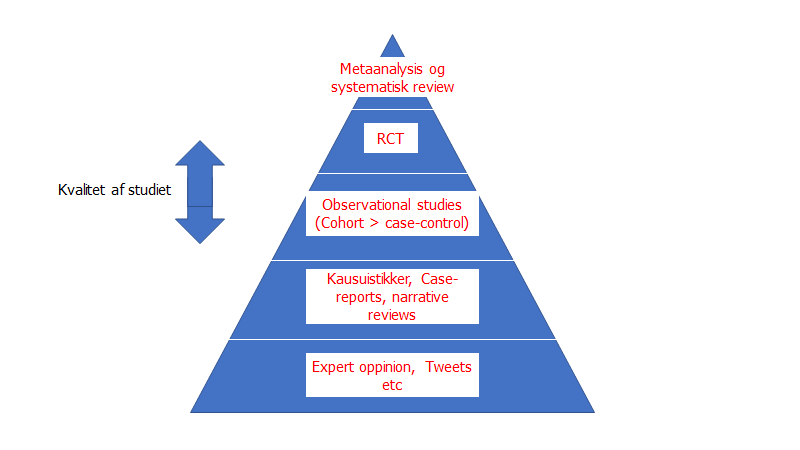
Pyramidens hieraki: Gordon Guyatt forklarer grundigt, at pyramiden ikke skal se som en absolut sandhed. Hvert niveau har deres svagheder, og selvom RCT’er er de bedste studier vi kan udføre for kliniske spørgsmål, så er de (som vi skal se herunder) langt fra perfekte – særligt ikke i hænder med interesse i et positivt resultat. Dertil kommer, at for nogle kliniske spørgsmål vil visse studiedesign være umulige-, uetiske- eller ekstremt dyre at udføre
Det kan være enormt vigtigt at lære at tænke over det: man kan ikke lave studier på alt. Tag fx en udtalelse som “du må ikke knække fingre / knoer – du får gigt af det”. Hvordan vil du kunne teste det? Der findes en Ig-nobel pris givet til en person der i en stor del af livet kun knækkede fingre på en hånd. Men det er svært at sige, at det er hård evidens eller at det er generaliserbar viden. At udføre et klinisk studie til at besvare spørgsmålet (får man gigt af at knække fingre?), er med andre ord næsten uopnåeligt, og selv hvis vi kunne, vil den investering formentlig ikke give noget relevant afkast, der forsvarer den enorme investering (hvis du nogensinde i guidelines har set “level x”-evidens, så er det ofte fordi man har indset, at det pågældende spørgsmål formentlig aldrig bliver bevaret)
Man foreslår derfor, at EBM-pyramidens kategorier, skal ses med overlappende kanter mellem hvert niveau, forstået på den måde, at et dårligt lavet RCT er lavere hieraki end et godt observations studie
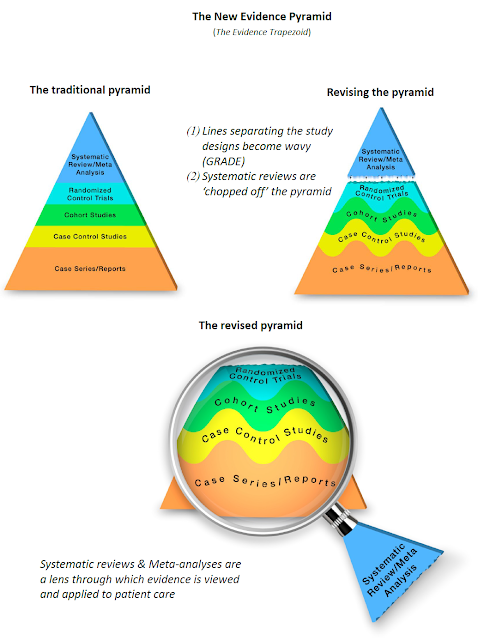
Andre mener dog, at hierakiet ikke bør være et hieraki overhoved, fordi det handler mere om “ret værktøj” til ret sted. Dette er bestemt ikke forkert – og på mange måder bør vi nok se studierne mindre som et stærkt hieraki og mere som en værktøjskasse til at løse forskellige problemer / kliniske spørgsmål: Skal du slå et søm i, kan det lade sig gøre med en sko, men det går bedre og du vil få højere kvalitets resultat, hvis du gør det med en hammer. Jeg vil dog pointere, at “hierakiet” fortsat eksisterer, formentlig fordi RCT’en er den bedste metode i langt de fleste tilfælde, for de spørgsmål vi stiller os klinisk, og hierakiet er således formentligt stærkest ift at beskrive “risk of bias”, når metoderne er anvendt optimalt. Er RCT’er dog ikke “pragmatiske”, vil den “laboratorie”-agtige måde RCT’er udføres på, være svære at generalisere til andre steder – endda på samme afdeling udenfor RCT-experimentet (jf fx Hawthorne effekten)
RCT Vs observations-studier: RCT er ikke perfekte , men mange bias reduceres ved randomiseringen, hvilket er en af de primære styrker ved RCT . Mange af de bias ser vi ved observations studier . Fordi de fleste ting vi studerer har små effekter (NNT fx >20-80) – de store effekter er ofte åbenbare og allerede opdaget) så er det ofte vitalt at man lader andre variable være konstante . Udfordringen som man skal være opmærksom på med fx observations studier , expert råd og case studier er bl.a at variable som fx “socioøkonomiske forskelle” ofte er så enormt mere kraftfulde end det man forsøger at teste (hvilket ofte fører til “selektions bias”). Et klassiskt eksempel er dette : Hvorfor observerer vi at hormonterapi virker til at sænke risikoen for hjertekar sygdom hos dem der tager det ? Da man lavede RCTen blev det tydeligt at forskellen var pga confounders som socioøkonomisk status (sundere personer med overskud går til lægen og er informeret om hvad nyhederne skriver, og får derfor oftere udskrevet terapien ). Problemet med observation er at det ofte er meget intuitivt (jeg ser at de der får det bliver bedre), og som vi skal tale om i del 1b (Medical reversal) så kan det være svært at overbevise etiske komiteer og befolkningen om en RCT efter observationer har indført det som standard behandling . Observationer er dog ikke værdiløse (langt fra – expertise bygges til dels på refleksion over vores observationer !) , men i forskningskontekst er de særligt hypotese genererende til test på anden vis eller i flere forskellige settings (kilde: bøgerne – testing treatments og overdiagnosed)
Vil du vide mere, om fordelene- og begrænsningerne af hvert studieformat, på en ikke-lærerbogs agtig, klinisk relevant måde, tjek da First10Em, SGEM eller St emlyns artikel gennemgange, hvor de ofte i slutningen forklarer om fordele og ulemper ved det pågældende studies design.
Lærerbøger jeg kan rekommendere som er gode, er fx Gratis bogen fra Ian Chalmers (Cochrane), “testing treatments” (link herover), eller biblen (users guide to the medical litterature) af Gordon Guyatt (link til gratis e-bog herover af den også)
Meta-analyser og pie’s: Toppen har traditionelt været metaanalyser (undertiden N = 1 studier, men dette blev droppet), selvom det er debaterbart. systematiske reviews og Metaanalyser er uden tvivl enormt vigtige. Er du i tvivl, så hør Ben Goldacre eller Ian Chalmers forklare passioneret om, hvad the Cochrane Library logoet betyder (metaanalyse over børns dødelighed med eller uden steroid behandling in utero – metaanalysen viste, at der fandtes en fordel ved at give behandlingen, hvilket har ført til tusindvis af reddede liv).
Problemet med metanalyser og systematiske reviews er dog sammenfattet i Dr Ken Milnes (SGEM) pointe om konceptet “garbage in, garbage out” om metaanalyser: Hvis du vil lave en god gryderet, så kræver det gode ingredienser. Smidder du pludseligt affald i gryden, kan det ødelægge hele retten. Noget som Ken Milne forklarer således:
If you want to make a tasty apple pie you need high quality ingrediens:
If you want to make a great metaanalysis you need great studies (= high quality)
If you want to make a great RCT you need great methods (= high quality)If you don’t have great methods / studies with great methods you can end up with a cow pie [ko-kasse] (poor quality study).
Ken Milne (SGEM), paraphrasing (se fx 47:00-50:00 i dette webinar)

Dette er en enormt vigtig pointe!
Årsagen til at metaanalyser vælger at tage lav-kvalitets studier med (fx observations studier eller dårlige RCT’er) er ofte for at “kaste et bredt net” (få hele forskningsfeltet med), og/eller for at øge poweren (Jo flere patienter, des større power , des lavere / mere “signifikante” p-værdier). Se linket i quoten herover, for at høre Ken Milne give et eksempel på dette indenfor trombolyse af stroke og Emberson metaanalysen. Pointen er dog denne (som bliver en gentagelse igennem bloggen). P-værdien (din æble tærte) er kun så meget værd, som de ingredisenser, der gik ind i at skabe den. Tager du skrald med (garbage in), får du skrald ud (garbage out). Husk det når du fortolker p-værdier
Ioannidis har lavet en meta-metaanalyse, og kommet frem med sin “meta-pie”:
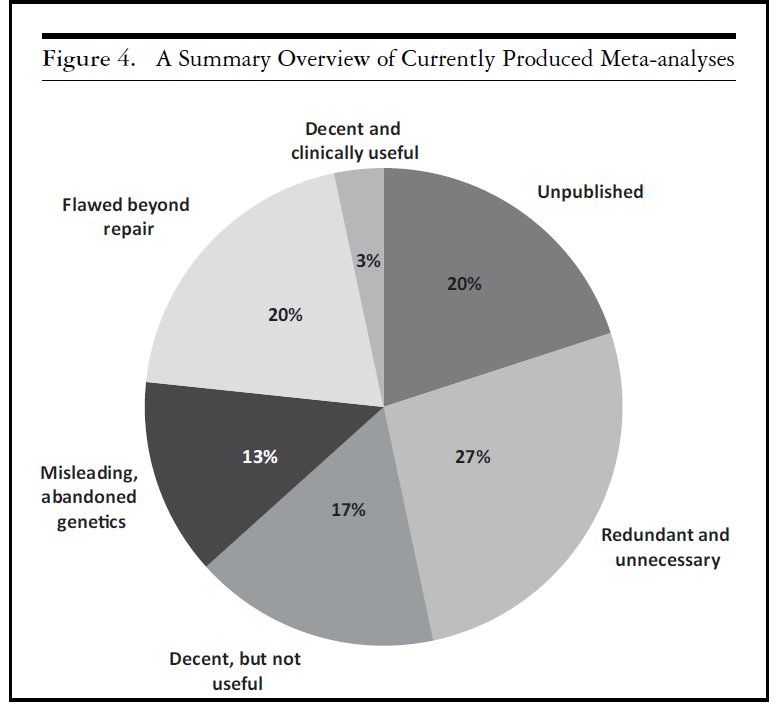
Ud fra Ioannidis’ analyse (The Mass Production of Redundant, Misleading, and Conflicted Systematic Reviews and Meta-analyses, 2016), er bare 1/5 metaanalyser af acceptabel kvalitet, og
kun 3% af alle metaanalyser er af acceptabel kvalitet, og klinisk brugbare (fx søger at svare et relevant klinisk spørgsmål etc)
Chasing significance

It’s not about banning big pharma – it’s about making their cheats irrelevant . People are not bad . It’s just a bad system that needs to be fixed and have rules and oversight
Ben Goldacre, youtube: How Drug Companies Mislead Doctors and Harm Patients
Det lyder slemt ud fra overstående diskussion – men guidelines bygger vel på studier som er signifikante?
I en ideal verden…ja. Men hvad er signifikans? Ofte vil mange svare, at statistisk signifikans er p<0,05 og/eller 95% Confidens interval uden indeholdende 1.
I de seneste år, er vi dog gået mere og mere væk fra denne falske dikotomi med studier som værende signifikante (eller positive) eller ikke-signifikante (negative). (se fx her, her eller her)
Ioannidis mener, at vi stadig behøver “signifikans”-begrebet som et slags kvalitetsstempel, for ellers ville alle hævde, at deres studie var vigtigt. Essensen er dog, at vi ikke forvirres af begreberne, og vi ser probabilstisk (i stedet for dikotomt) på det (mere om dette i EBM 2.0 delen herunder). Lad mig give et eksempel på hvordan vi ofte på et sprogligt niveau. Der findes en vigtig pointe hér med “vigtighed” og “signifikans”, som vi ofte forveksler, som Jerome Hoffman forklarer
We confuse statistical significant with “important”. When you read[…]that it was “significant “ most people think it mattered. Almost all of what we study in medicine doesn’t matter[…]
there are two reasons why you could get a statistical significant result: one is there is a trivial difference and you have enough people to find it (or just by chance ) and the other is there’s a big difference . Big differences we almost never need to study – they are obvious [i.e “golden bullets”]Jerome Hoffman, Youtube: Reader Beware: Common Study Pitfalls
To pounce on tiny P values and ignore the larger question is to fall prey to the “seductive certainty of significance”, says Geoff Cumming, an emeritus psychologist at La Trobe University in Melbourne, Australia. But significance is no indicator of practical relevance, he says: “We should be asking, How much of an effect is there?’, not ‘Is there an effect?’”
Nuzzo, 2014: Scientific method: Statistical errors
Dette er enormt vigtigt:
- p-værdi <0,05 betyder ikke at resultatet er vigtigt eller meningsfuldt klinisk: at noget er “statistisk signifikant” betyder ikke, at det er meningsfuldt. NNT = 10000 på et surrogat outcome for at behandle med stof x. Men der er en signifikant forksel ift placebo, fordi man har medtaget millioner af folk. På populationsbasis kan dette være relevant. Men hvad er harms? og giver det virkelig mening for patienten (POO)?
- At “store forskelle” er sjældne, fordi vi ofte allerede har fundet de vigtigste store forskelle ved rationalisme (Fx insulin – såkaldte “parachutes”. Man behøver ikke teste falskærme for at vide, at de virker. Men kun få ting i medicin er “faldskærme”). Store forskelle (som anand senthi nævner), er oftest pga små studier, og er ikke reproducerbare når de store studier laves
- Meta-analyser vil ofte “pumpe” deres studier op ved at tilføje masser af patient-rige studier. Således kan de få statistisk signifikans for næsten hvad som helst (se p-hacking og Janus fænomenet). Dette er Ken Milnes “apple pie” analogi. Metaanalysen er en apple pie, og hvis du smider dårlige æbler i, så får du måske signifikans, men ingenting du kan stole på (eller vil købe)
…Men der er flere problemer med begrebet “statistisk signifikans”. Følgende er et mere “forsknings-kulturelt problem”, som du måske aldrig har hørt på, men er gennemgribende vigtigt: En mere skjult måde konceptet (dikotomien) “signifikans” giver problemer på, er igennem det Ioannidis kalder “Significance Chasing Bias”.
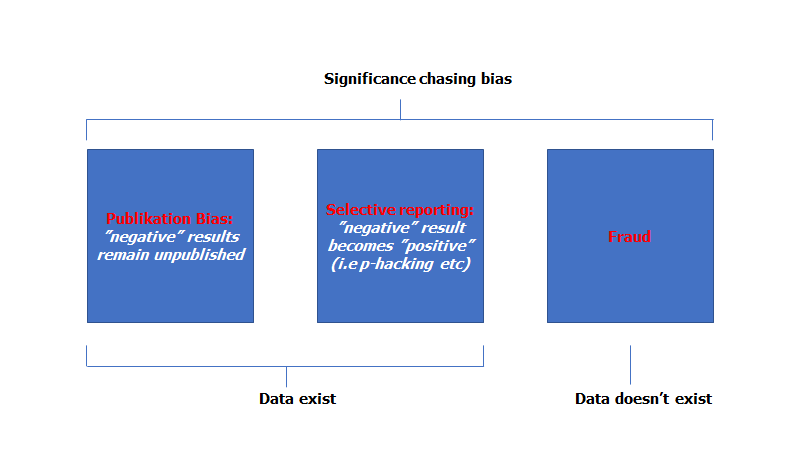
Overstående figur er taget fra Ioannidis’ lektur kaldet “The Challenges of Evidence-Based Medicine“. Optimalt forsøger forskere at modbevise sig selv gennem udfordring af 0-hypotesen. Men som vi har set med i mange andre instanser, så er forskning og medicin ofte en social sport mere end en logisk (se fx Nugus et al hér og hér: Selling patients). Resultater kræves og uanset hvor puristisk en forsker man er, så vil et positivt resultat (desværre) se bedre ud for din karriere end et negativt resultat (selvom dette er groft imod de videnskabelige objektivitet). Med andre ord, er du underbevidst (mere end bevidst) presset til at dine resultater bliver “positive” eller “signifikante” og deraf dit bias: Significance chasing bias, som kan være tredelt.
Medicine is a social science, and politics is nothing more than medicine on a large scale
Virchow
1: “Fraud” er ekstremt sjældent, og jeg vil ikke nævne mere om dette.
I stedet er det ofte de to andre kategorier som er årsagen til mange problemer i researchs brugbarhed. Ben Goldacre har skrevet en hel læsværdig bog om disse to begreber, Publikations bias og selektiv rapportering (Bad Pharma) og beskriver dem ikke som “fraud”, men ufint spil som vi (desværre) har gjort det nødvendigt for research- og pharma at udføre for at overleve:
The cheats are small tweaks at the border of cheating . Adding up to a snowball effect
Ben Goldacre, Youtube: How Drug Companies Mislead Doctors and Harm Patients (2013)
Det er lidt som alle cykelryttere doper sig i Tour de France. Alle ved, at det forekommer, og spørger du den enkelte cykelrytter, vil de sige nej. Men det er pga os, der gerne vil se “hurtigere, stærkere, større” cykelløb, at kulturen er blevet så ekstrem, at de er nødt til at dope sig.
2: Publikations bias: Dette har jeg allerede beskrevet kort, og jeg anbefaler Bad Pharma eller lekturer af Goldacre for at forstå den aktuelle status af dette problem:
Publikationsbias beskrives oftest fra “studie-niveauet”. Altså at man ikke publicerer negative studier. Har et firma lavet 20 studier og 19 blev negative, kan de gemme dem i skuffen (de får en bøde for ikke at registrere, men den kan betales fint hvis det 1/20 positive studier giver et resultat, som gør dem rige). Dette giver en skævvridning, da vi behøver alle studier (al data) for at vide, hvad netto effekten er. Selvfølgelig findes der en hvis “trial and error”-teknik i dette også, men data burde være tilgængelige ikkedestomindre.
Men vi taler sjældent om publikationsbias i det enkelte studie (se også p-hacking herunder). Kort sagt, så forestil dig at et studie laves, hvor du fjerner alle de dårlige datapunkter der ikke tiltaler dig (lidt som med de negative studier). Mange ville kalde dette “fraud”. Set fra en meta-analyses perspektiv (hvor ét studie er et datapunkt), er det præcist, hvad der gøres når man ikke publicerer data (…som så godt som altid vil være negativ studier, hvilket fører til en ekstrem “positiv” skævvridning, og den absurde statistik om 96% p-værdier er “positive” i pubmed). Om metaanalyser er der rigtigt sagt: “a stew is only as good as the ingredients” – har vi ikke alle resultater (og har vi ikke sorteret godt nok i ingrediensernes kvalitet), vil “stewen” være irrelevant. Selektionen af datapunkter er et enormt problem som også går ind under paraplyen af publikationsbias:
3: Selective rapportering: Organisationer med interesser for at få “positive” resultater (i stedet for at teste 0-hypotesen – begrebet “Fair Test” er vigtigt her, som beskrevet i “testing treatment”-bogen, gratis link herover) vil i tvetydige situationer (bevidst eller ubevidst) gå imod at sortere resultater så sandsynligheden for at det bliver “positivt” er mere sandsynlig. Et lille udsnit af Ben Goldacres forord til Cochranes Testing Treatment bog:
If there is one key message from this book – and it is a phrase I have borrowed and used endlessly myself – it is the concept of a ‘fair test’. Not all trials are born the same, because there are so many ways that a piece of scientific research can be biased, and erroneously give what someone, somewhere thinks should be the right’ answer. Sometimes evidence can be distorted through absent- mindedness, or the purest of motives (for all that motive should matter). Doctors, patients, professors, nurses, occupational therapists, and managers can all become wedded to the idea that one true treatment, in which they have invested so much personal energy, is golden.
Ben Goldare (Foreword) til gratis bogen Testing Treatments
Sometimes evidence can be distorted for other reasons. It would be wrong to fall into shallow conspiracy theories about the pharmaceutical industry: they have brought huge, lifesaving advances. But there is a lot of money at stake in some research, and for reasons you will see in this book, 90% of trials are conducted by industry. This can be a problem, when studies funded by industry are four times more likely to have a positive result for the sponsor’s drug than independently funded trials. It costs up to $800m to bring a new drug to market: most of that is spent before the drug comes to market, and if the drug turns out to be no good, the money is already spent. Where the stakes are so high, sometimes the ideals of a fair test can fail.
Equally, the way that evidence is communicated can be distorted, and misleading. Sometimes this can be in the presentation of facts and figures, telling only part of the story, glossing over flaws, and ‘cherry picking’ the scientific evidence which shows one treatment in a particular light.
But in popular culture, there can be more interesting processes at play. We have an understandable desire for miracle cures, even though research is frequently about modest improvements, shavings of risk, and close judgement calls. In the media, all too often this can be thrown aside in a barrage of words like ‘cure’, ‘miracle’, ‘hope’, ‘breakthrough’, and ‘victim’.
At a time when so many are so keen to take control of their own lives, and be involved in decisions about their own healthcare, it is sad to see so much distorted information, as it can only disempower
Det er altså ikke altid tale om gemene planer, men oftere biases pga interessekonflikter, der får os til (bevidst eller ubevidst) at vælge det der er i vores egen interesse. Hér er konklusionen på blot et et nyligt studie på området
Systematic reviews with financial conflicts of interest more often have favourable conclusions and tend to have lower methodological quality than systematic reviews without financial conflicts of interest
Hansen et al, Cochrane, 2019: Financial conflicts of interest in systematic reviews: associations with results, conclusions, and methodological quality
Nogle eksempler på hyppigt forekommende metoder som ofte anvendes til at “booste” p-værdien er som følger (se fx Jerome Hoffman, Ioannidis, SGEM, First10Em eller Ben Goldacres kilder herover, for en mere udtømmende liste). Dorothy Bishop (psykolog), kalder særligt 4 af disse problemer (publikations bias, p-hacking, bad design of studies / irrelevant questions asked og “HARK”) for “the 4 horsemen of the apocolypse”
P-hacking,” says Simonsohn, “is trying multiple things until you get the desired result” — even unconsciously.
Nuzzo 2014: Scientific method: Statistical errors
- P-hacking: For at forstå p-hacking, og hvordan man kan “plukke” de resultater, som er mest favorable for os, se Ioannidis’ eksempel med Janus fænomenet (20:50) eller “dance of the p-values“
- Bytte af “primary outcome”: Som SGEMs Ken Milne siger – primary outcome: there can be only one. Har man pludselig mange outcomes (ofte sekundære, men også ofte primære), så vil sandsynligheden for at mindst en af dem er positiv (jf janus fænomenet herover), tiltagende sandsynlig. Ligeså alvorligt er der mange studier, der ændrer deres primær outcome under studieforløbet (dette kan være relevant, men sænker vores tiltro til resultatet – dette gøres i >50 % af studierne!)
- Stoppe studiet før tid: Dette er kun tilladt med objektive interrim-analyser uden interessekonflikt. Stoppes et studie før tid, ved du aldrig om man valgte at stoppe det lige præcis når det så godt ud for stoffet som testes. Se Fx PRISM studiet fra Rebel EMs gennemgang
- Surrogat-outcome Vs Patient-relevante outcome: Surrogat outcome er lettere (og billigere) at måle på, men er ofte ikke det, som patienten synes er vigtigt. Ofte vil papers i deres konklusion lave stor mægnde hybris når de beskriver vigtigheden af deres signifikante surrogat outcome. Meget få surrogat-outcome (hvis nogen) er stærkt kausalt korreleret til ægte outcome. Jerome Hoffman giver eksemplet med: har patienten med appendicit leukocytose (surrogat outcome), vil vi vel ikke plasmafarere (fjerne leukocytterne) hende. Alt for ofte er surrogat-outcome et konstrukt af vores paradgime (…but it makes sense physiologically) – noget vi tror hænger sammen med det vi ønsker at undersøge, men sjældent gør det.
- HARK (Hypothesis After Results are Known) / Post-hoc analyse: Vi ved, at post-hoc analyse (at efter resultatet af studiet er kommet, og er negativt, at finde en subgruppe som måske var signifikant) som udgangspunkt ikke må anvendes til andet end “hypotese-generation”. Ben Goldacre påminder os om en vigtig pointe i post-hoc analyse logik: såfremt nogen hævder, at post-hoc analysen gør, at vi skal anvende denne behandling, så kan man sige følgende: såfremt post-hoc analysen er sand (at en subgruppe har fordel), så må den resterende gruppe som er tilbage efter sub-gruppen er fjernet, nødvendigvis tage skade af behandlingen (“benefit in one subgroup means harm in another“). Ellers passer gennemsnittet ikke – når en ting går op, må den anden gå ned, hvis resultatet i studiet skal stemme.
- Double gold-standard: Hvad testes testen imod? Ofte er dette en cirkel argumentation (test af POCUS for pneumoni hos børn – hvad er goldstandard? røntgen? CT?…hvad var det nu pneumoni var igen? Hvilke pneumonier er det vi gerne vil finde?). Jerome Hoffman forklarer, at der ikke findes en “gold standard”, det er blot noget vi finder på. Ofte vil studierne ikke udføre “gold-standard” testen fordi den er harmful, og dette giver ofte en “double gold-standard”-problemstilling. Et eksempel på dette, er SAH studier, hvor alle med TCH (thunderclap headache) får lavet en CT, og derefter følges op. Nogle får LP og nogle går videre til at lave en masse andre udredninger. Her findes der altså forskellige definitioner af, hvad man mener er “gold standard” (CT og follow up Vs CT, LP, CT angio etc). Vi kan her aldrig være sikker på, at vi ikke misser relevante cases i den ene gruppe
- Test lav-prævalens grupper (spectrum bias): Lad os sige, at jeg har en magisk kæp, som skal undersøge, om en patientgruppe har AKS. Hvis jeg går ud en dag i byen på gaden og “tester” alle med kæppen, vil jeg meget sikkert ikke finde nogen med AKS. Testen er altså fantastisk! Den har en 100% sensitivitet. Med andre ord handler det virkelig om, i hvilken gruppe vi anvender vores test. En test der skal anvendes på akutmodtagelsen må med andre ord, også være testet i denne population. Case-raten i studiet skal være det samme som jeg har på min akutmodtagelse. Ellers er det en “for rask” befolkning (se fx https://first10em.com/crash-3/)
- Test imod placebo: Test din behandling imod placebo er ofte en god idé, hvis intet bedre findes…men findes der noget bedre (fx en konkurrents behandling) er det etisk forkert at teste imod placebo. Dog sker dette ofte. Farma-firrmaer gør atl de kan for ikke at blive testet imod en konkurrent eller en anden behandling som er gået af patent (fx paracetamol). Det er lidt som bilfabrikanter sjældent synes om, når deres biler kører i top-gear “head-to-head”, da de har for meget at tabe hvis deres bil ikke er hurtigst. Når de testes og en er bedre end en anden må man i stedet argumentere at “vores bil er bedre i svingene” eller lignende (i medicin: færre bivirkninger, billigere etc etc). Jeanne Lenzer beskriver i the danger within us en særlig problematisk situation med “grandfathering”-konceptet: Mange stoffer skal bare bevise, at de er non-inferiore til noget der allerede er på markedet (“grandfathers-drugs”). De stoffer (eller devices) der allerede er på markedet, blev godkendt på en lav standard (ofte i 50’erne eller 60’erne) som vi i dag vil mene er lav evidens. Men vi har ikke retro-aktivt krævet at beviset for disse stoffer følger den standard vi vil have i dag. Dette har ført til den absurde situation vi ofte ser, hvor et stof der skal godkendes ønsker at “ligne” grandfatheren nok til at være “sammenlignelig”, men samtidig er forskellig nok til ikke at være det samme drug (kilde: The danger within us)
Et andet koncept som jeg ikke selv har kunnet finde et svar på, er problemet med at placebo ikke er én størrelse, men som Wayne Jonas og Daniel Moerman forklarer fx i studiet “Cultural Variations in the Placebo Effect: Ulcers, Anxiety, and Blood Pressure”, at placeboeffekten (meaning response) ikke er én ting. Den varierer alt efter populationens kultur (fx er blå piller noget, der får folk til at slappe af, i alle andre lande end Italien, hvor den blå farve leder tanker imod fodboldlandsholdets trøje, og derfor har modsat effekt) og individets forventninger, samt lægens empati. Vil du have den ringest mulige placebo effekt i et studie, så skal du bare være et uempatisk, koldt svin imod patienten ifølge Jonas (se en gennemgang , og vær skeptisk herunder med Jonas, som er en kontroversiel figur). Men hvis placeboeffekten ikke er én ting som standardiseret kan anvendes i studier, og som formentlig er forskellig fra deltager til deltager – hvad er så støj og signal i studier? Desto større grund til at behøve et ordentligt signal – de store sten – og ikke lede efter grus som formentlig ikke kan repliceres.
Mange af overstående elementer kan sagtens være relevante i et studie – de forklares desværre sjældent overt. Dette må antages at være fordi konsekvensen af at anvende dem er, at kvaliteten / tyngden med hvilken vi burde tro på studiets resultater (fair test), falder (ofte betydeligt). Problemerne kommer dog ofte i et senere skridt: konklusionen og i markedsføringen (og sidenhen i aviserne), hvor der tillægges en stor hybris på resultatet, som føres videre til befolkningen, patientorganisationer, poltikere og guidelines
Vær opmærksom på, at overstående elementer ofte er “metode”-problemer. Som jeg har beskrevet, så vil mange af de moderne studier fra industrien “tick all the boxes” (fordi de ofte spiller efter reglerne, når man sætter dem op!). De oftest vigtigere spørgsmål er noget man ikke kan sætte fingeren i selve studiet, men snarere er noget du som kliniker må spørge dig selv ud fra din praksis
- Er spørgsmålet der stilles i studiet, klinisk relevant?
- Er outcomet der måles på POO Vs surrogat?
- Hvilke Bias (skjulte og ikke-skjulte) findes der? “is it a fair test”?
- Har forfatterne interessekonflikter (fincielle- og interlektuelle)?
You can think of a trial like a race. We want the race to be fair. In order to be fair, the race has to have a fair start (all patients start the trial at the same spot), everyone needs to run the same course (all trial participants are treated similarly except for the intervention), and there needs to be a fair finish (the outcome is measured the same for everyone, without bias).
First10Em: EBM is easy
The inverse benefit law […] states that the ratio of benefits to harms among patients taking new drugs tends to vary inversely with how extensively the drugs are marketed. The law is manifested through 6 basic marketing strategies: reducing thresholds for diagnosing disease, relying on surrogate endpoints, exaggerating safety claims, exaggerating efficacy claims, creating new diseases, and encouraging unapproved uses.
Donald Light et al: The Inverse Benefit Law: How Drug Marketing Undermines Patient Safety and Public Health
Og måske vigtigst af alt for klinisk anvendelse
- Er studiet vigtigt for den person i min afdeling jeg har foran mig? (extern valideringen), og hvad var inklusions / eksklusionskriterierne (i.e ville min patient kunne være med?)
Vil du selv blive bedre, så tjek mine råd herover (under research -> punkt 1-7). Har du et paper foran dig nu, så start gerne med First10Ems RAMBO metode og/eller St emlyns CAN og/eller CASP og/eller sketchy EBM:
Essensen er at læse metoden først for at forstå om du overhoved burde læse resultatet. Er metoden god og PICOS relevant, kan du læse resultatet. Intro, diskussion og konklusion er oftest irrelevant.
Det er til slut hér vigtigt at pointere, at vi har skabt dette system uden regulationer. Det medico-industrielle-kompleks gør bare det logiske. De er ikke onde. Faktisk plejer Ben Goldacre at pointere, at hele “marketing”-delen (som jeg ikke har gået ind i denne gang – dvs reklamering for at sælge drugget), ikke behøvedes, hvis ikke vi i moderne medicin er så enormt dårlige til at opdatere vores lægers viden i.e 17 år fra god evidens til klinisk anvendelse (hint til “læringsbloggen” her på akutmedicineren)
Fortolker vi, selv veludførte studier, forkert?
Many medical practices are not soundly based. They are sustained, as is true of other human pursuits, by an intertia supported by fashion, custom and the word of authority. The security provided by a long-held belief system, even when poorly founded, is a strong impediment to progress.
Bernard Lown, The Lost art Of Healing
General acceptance of a practice becomes the proof of its validity, though it lacks all other merits. In the words of French physiologist Claude Bernard, the innovator’s talent is in “seeing what everybody has seen, and thinking what nobody has thought”.
Once a new paradigm takes hold, its acceptance is extraordinarily rapid and one finds few who claim to have adhered to a discarded method. This was succinctly captured by Schopenhauer, who maintained that all truth passes through three stages: first, it is ridiculed; second it is violently opposed; and finally, it is accepted as being self-evident
Anand Senthi, udkom nyligt med sit EBM2.0 koncept, som bl.a bygger på Ioannidis’ papers (obs: Josh Farkas fra PulmCrit har lavet lignedne argumenter om p-værdier)
Han har lavet en video om hvorfor i sin EBM 2.0 kampagne, som alle med interesse for feltet, bør se (som også findes som podcast via Broomedocs, og beskrevet via First10Em):
Selvom jeg anbefaler dig at se hele videoen, og tjekke hans hjemmeside (EBM2point0), så vil jeg lige sammenfatte det vigtigste.
P-værdier er ikke dikotome (signifikante Vs ikke-signifikante). De bør optimalt betragtes som likelihood ratios ud fra følgende skema
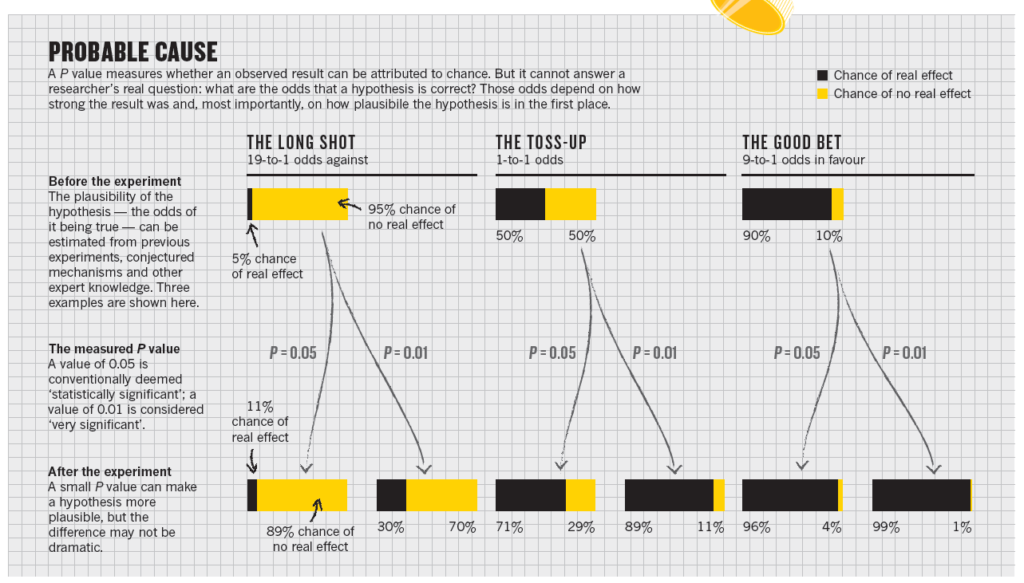

Det er i den forbindelse essentielt at vide, at p-værdien vi finder i studierne er et best guess og formentligt skal vi tage værdien i sig selv med et gran salt.
p-værdien i sig selv tager nemlig ikke højde for bias.
Most scientists would look at his original P value of 0.01 and say that there was just a 1% chance of his result being a false alarm. But they would be wrong.
The P value cannot say this: all it can do is summarize the data assuming a specific null hypothesis. It cannot work backwards and make statements about the underlying reality.That requires another piece of information: the odds that a real effect was there in the first place. To ignore this would be like waking up with a headache and concluding that you have a rare brain tumour — possible, but so unlikely that it requires a lot more evidence to supersede an everyday explanation such as an allergic reaction. The more implausible the hypothesis — telepathy, aliens, homeopathy — the greater the chance that an exciting finding is a false alarm, no matter what the P vlaue is
Nuzzo 2014: Scientific method: Statistical errors
…
More broadly, researchers need to realize the limits of conventional statistics, Goodman says. They should instead bring into their analysis elements of scientific judgement about the plausibility of a hypothesis and study limitations that are normally banished to the discussion section: results of identical or similar experiments, proposed mechanisms, clinical knowledge and so on
The numbers are where the scientific discussion should start, not end
Du ved med andre ord ikke, om den test, som p-værdien kommer fra er en fair test eller ikke (justin morgenstern fra First10Em giver i starten af denne EmCases podcast en gangske god analogi til dette): I et løb melem to modstandere (behandling A og B), vil p-værdien ikke sige noget om A løber opad bakke, har tunge blyklodser om benene eller ikke er fit. Vi skal altså vurdere om testen er fair og hvilke bias der findes (der er altid bias), og have det med i baghovedet, når vi læser p-værdiens resultat.
Når vi taler LR (som nu er sådan vi skal tænkte p-værdier), vil den bevandrede i probabilisme vide, at vi kræver en præ-test sandsynlighed: Alle studier bør argumentere for præ-test sandsynligheden i studiet, og hvorfor det er tilfældet.
Prasad og Cifu: Medical Reversal
Dette ville desuden måske løse et af de problemer, der findes med irrelevant research: en af årsagerne til irrelevant research ifølge Ioannidis er, at man ikke har gjort forarbejdet og reseaerched hvordan ens studie vil bidrage / passe ind i den viden vi allerede har. Intuitivt giver dette mening ift hvad Hans Rossling (i Factfullness) som en hverdags-tommelfingerregel fortæller os: når vi ser et tal, skal vi altid spørge, hvad det tal hører sammen med (Statement: Det bliver 20% koldere i dag…i forhold til hvad? i går? hvad var temperaturen i går?. Statement: 200 døde i år i trafikken…er det meget? er det lidt? Hvad var baseline de sidste årtier?)
En gennemgang af hvordan dette koncept skal appliceres til al research vi fortolker (“hvad er præ-test sandsynligheden?”) findes hér eller på BroomeDocs podcasten med Anand Senthi

Lad os slutte med et eksempel: Lad os sige, at en af dine kollegaer viser dig et studie, hvor p-værdien er 0,01, og man synes at I skal indføre det på afdelingen af den grund. Udover at kigge på om spørgsmålet i studiet er relevant, og outcomet er patientorienteret, og at metode-designet er relevant ift at besvare det spørgsmål etc etc (se RAMBO first10Em for en systematisk gennemgang), så spørger du, hvad præ-test sandsynligheden er? Er dette en novel-terapi, hvor vi kun har “fysiologiske argumenter” at gå på? Så vil præ-test sandsynligheden for at resultatet kan stoles på måske kun være 5-10 %. Post-test sandsynligheden kan vi se ud fra tabellen herover, er 47%. Ikke dårligt, såfremt studiet er vellavet og RAMBO-gennemgangen er god nok ift Bias. Efter denne gennemgang synes du, at p-værdien er højt sat, og du fratrækker derfor nogle procent fra post-test sandsynligheden til en korrigeret ca 30%. Fint, men kræver flere studier.
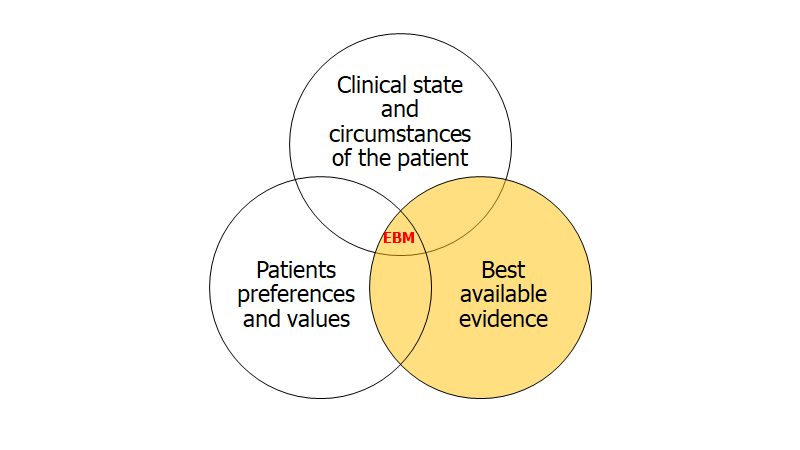
Husk herefter på at ifølge EBM (se hér og hér for hurtig gennemgang) er dette kun 1/3 af det, der er en evidensbaseret beslutning. De to andre dele er patient values (som jeg gennemgår nu og i del 2), og den kliniske situation og bedømningen af den (som jeg har gennemgået i mine decision making blogs fx akutmedicineren best of 2020, og som til dels også vil berøres i del 2 af denne blog)
2: Fra research til klinisk praksis
“Grandfathering”: et eksempel på reguleringensorganets huller
Jeg tænker ikke at gå dybt ind i selve regulationen af medicin via FDA og EMA. Vil man høre detaljeret kritik om dette kan jeg stærkt anbefale hhv Jeanne Lenzer og Ben Goldacre / all-trials (se kilder herover)
Et koncept, der kan være essentielt at kende til er dog “grandfathering“. FDA fik først ansvar for devices i USA i 1976. Alle devices lavet før 1976 (Fx pacemakers, nervestimulatorer etc), er således godkendte uden nogen for for trials, og blev ikke retro-aktivt krævet at bevise deres effekt (eller harm).
Et smuthul for mange devices implementering, er derfor blevet “grandfathering” (510K-pathway) som Jeanne Lenzer beskriver i sin bog (The danger within us, og som hun også taler om i podcasten med Ken milne – særligt 9:00-20.00). Essensen her er, at dit nye device skal ligne et gammelt godkendt drug nok til at være sammenligneligt (men alligevel være nyt nok til at kræve egen patent) – såfremt det lever op til dette krav, så behøver du ikke lave trials eller bevise dens effekt (selvom “the grandfather device” som du bygger dit argument på, aldrig har været bevist at virke- og aldrig er testet for harm. Det er et såkaldt “house of cards”). Mange nye devices er altså designet efter denne regel, og fordi vi aldrig har kontrolleret de gamle devices, behøver vi ikke at gøre det med de nye heller. En stor del af devices går igennem denne vej for godkendelse – vi taler ikke nogle få stykker. Der er devices du bruger dagligt som sandsynligvis er gået igennem denne vej.
En lignende problem har Ben Goldacre gjort opmæksom på via sin All Trials kampagne – alle studier på “drugs” før 2004 er ikke registreret, og der er ingen retro-aktive krav om at publicere alle studierne (derfor navnet “all trials”). Igen, der er drugs du bruger dagligt som har så stort publikatiosbias, at det er umuligt at vide (men vi har indikationer på) at der findes større harms.
Dette er et af mange eksempler på “smuthuller” i systemet, og man kan ikke klandre nogen for det – det er det system vi har designet. Og skulle nogen protestere, så har anvender farma-industrien store mængder penge til at påvirke FDA (enten direkte eller indirekte gennem patientforeninger, kongresmænd og endda præsidenten) for at få deres stof igennem.
Skulle man i USA finde problemer med et stof eller et device efter det er blevet frigivet (hvilket i sig selv er svært, fordi industrien selv regulerer opsamlingen af data om dødsfald…som at lade en ulv vogte får), så betragtes det i FDA som en “trade secret”, og de må ikke gå ud til befolkingen med problemet (medmindre der kommer stærk evidens på det, hvilket kræver studier fra neutrale organisatioener- som folk ikke finder ud af skal laves, medmindre de finansieres. Hvem gider finanisere det?)
Et eksempel på dette kan man læse i Ryan Radeckis (EmLitOfNote) saga-agtige kritik af NOAK og særligt Rivaroxaban og Dabigatran (som Jerome Hoffman også har kommenterer på)
The FDA says that it is not allowed to tell us if a drug that is already being used is killing people. Because it is a “trade secret“
Jerome Hoffman, youtube: Head Trauma in the Coagulated Patient (quoting the BMJ)
Interessekonflikter i science
Both the FDA and the CDC both have patwhays through which they are funded by the industry
Jeanne Lenzer, SGEM Xtra om The Danger within us
Igen, kun kort tid jeg vil bruge på dette, da det er vel-belyst hvor meget penge gør vores forskning korrupt. Jonathan Haidt beskriver, at “essensen” (thelos) af universitetet / akademi er at “finde sandhed”, men når der kommer andre interessekonflikter ind, så ødelægges det ganske svært-opnåelige miljø, der skal til for at “finde sandheden” eller tilnærme sig den (for detaljer se RSA talken af Jonathan Haidt: Why a 21st Century Enlightenment Needs Walls).
Det er ikke fordi penge ikke må eksistere (det er formentligt umuligt – i hvert fald i vores nuværende moderne vestlige samfund), men vi behøver vægge, og systemet- og incitamenterne må re-designes (fx ved at det ikke er resultatet (neg vs pos), men kvaliteten af studiet, der gør at du får penge)
Et gennemgående tema for denne blog er, at vi selv har skabt det system, som vi har fået. Det system farma er født ind i, gør, at de er nødt til at være konkurrence mindede. Det er ikke fordi farma-personer er onde. Men konsekvensen for samfundet er oftest ufordelagtigt, og problemet med financielle interessekonflikter sammenfattes i en nødeskal af TIMI trials
We don’t know how another trial would turn out. And if we don’t come out ahead, we would have a tremendously self-inflicted wound . . . [another study] may be a good thing for America, but it wasn’t going to be a good thing for us
Om Alteplase firmaets holdning til nye trials efter deres første positive (men inkonklusive) TIMI trial (behandling af AKS med trombolyse). Quote fundet af Jeanne Lenzer og publiseret i the BMJ: Alteplase for stroke: money and optimistic claims buttress the “brain attack” campaign
Det kan siges ganske kort om finaniselle interessekonflikter: Hvis det ikke virkede, ville farma ikke anvende store dele af deres budget på det (eller som man siger “if you want a doctor to change behaviour, make the patient ask for it [i.e a new drug / device])
Interlektuelle interessekonflikter anvendes i stor grad af farma-industrien også, men er noget vi alle med vores personlige bias’es er nødt til at være opmærksomme på. Et eksempel er, hvis du er en “oppinion leader” som har forsket i noget hele dit liv. Ikke alene vil du være mere tilbøjelig til at se fordelagtigt på dit felt. Nogle gange vil du “by random accident” også være i overensstemmelse med et farma-firma i deres holdning om deres drug. De behøver ikke indoktrinere dig, de kan bare promovere dig og skabe dig en platform og give dig en megafon (som dine modstandere ikke har). Den ideelle megafon er fx guidelinespaneler. Derfor er guidelinepaneler nødt til at være blandet af folk med forskellig baggrund (herunder også patienter), og med så begrænset (og transparent) conflict of interests som mulig.
Det er naivt at tro, at folk ikke har interessekonflikter. Vi er nødt til at designe systemet, som Ben Goldacre foreslår, så magtkampe ikke bliver ligeså sandsynlige, og vi har mulighed for at kæmpe for det der er bedst for patienten uden al den enorme omkostning som vi har gang i lige nu
En sidste interessekonflikt værd at nævne, er den interessekonflikt der er for folk i fx FDA der senere gerne vil have job i industrien. Du ansættes ikke, hvis du har været kritisk / problematiseret godkendelsen af et stof.
Medical reversal: “Når hestene er løs, er det svært at få dem ind igen”
[Medical] Reversal occurs when a currently accepted therapy is overturned, found to be no better than the therapy it replaced. This often occurs when a practice – a diagnostic tool, a medicine, a procedure, or a surgical technique – is adopted without a robust evidence base.Many people dismiss this phenomenon [reversal] as the natural course of science: of cource hypotheses turn out to be wrong, and we can only move forward through trial and error. Altthough this is certainly true in biomedical science – where there are false starts, good hypotheses that fail to live up to espectations – it is not the case in medicine. Medicine is the application of science. When a scientific theory is disproved, it should happen in a lab or in the equivalent place in clinical science, the controlled clinical trial. It should not be disproved in the world of clinical medicine, where millions of people may have already been exposed to an ineffective, or perhaps even harmful, treatment
Prasad og Cifu: Medical Reversal (bog)
Et problem vi endnu ikke har berørt endnu, er når research godkendes og implementeres i klinikken, for hurtigt, men sidenhen (når gode studier udføres) viser sig at være farligt / dyrt og uden benefit, når det testes ordentligt (heri ligger der desværre en sandhed: vores regulation af, hvad der indføres er for dårlig jf fx The Danger Within Us). Når vi vælger at kalde den præmaturt indførte behandling tilbage, kaldes det Medical reversal – et koncept som er velbeskrevet i Prasad og Cifus bog af samme navn fra 2016.
Dette er kort sagt fordi farma-industrien kører samme handelsteknik som “scooterne” eller “uber” eller “sociale medier”. Implementer så hurtigt som muligt, skab et behov (lad patienten spørge om dit produkt hos lægen), og gør det så svært som muligt at føre tilbage. Hvis først er på markedet og behovet findes (selvom det ikke har grundlag i evidens), så er det enormt svært at få væk, og uanset om det en dag fjernes, så er det sandsynligvis først efter patenten er udløbet og du som firma alligevel er ligeglad.
Der er et hav af årsager til dette pres fra både patientorganisationer (som kan være desperate for “al hjælp”), til research (som elsker novelty, ikke reproduktion), til den medico-industrielle maskine der er benzin på bålet, til klinikere med financielle- eller interlektuelle interessekonflikter m.m.m.
Medical reversal ser vi ofte og endda på terapier vi lige nu anvender som “gold standard”. En gold standard som (desværre) ofte alt for ukritisk (og biased af interesse konflikter) copy-pastes til guidelines, som vi efterhånden kan anklages for, hvis vi ikke anvender på stadigt mere liberale patientpopulationer (indication creep), med dårligere og dårligere “chance of benefit Vs risk of harm”-ratio (looking at you trombolyse til stroke og liberal anvendelse af elektiv PCI).
Men hvor meget af vores praksis skulle “reverses”?
Flere har forsøgt at svare på dette spørgsmål (jf kilder herunder)
- Prasad et al, 2011: Medical Reversal: Why We Must Raise the Bar Before Adopting New Technologies
- Prasad, Cifu og Ioannidis et al, 2013: A Decade of Reversal: An Analysis of 146 Contradicted Medical Practices
- Herrera-Perez, Cifu, Ioannidis et al, 2019: A comprehensive review of randomized clinical trials in three medical journals reveals 396 medical reversals
Prasad og Cifu lavede i sin bog følgende oversigt
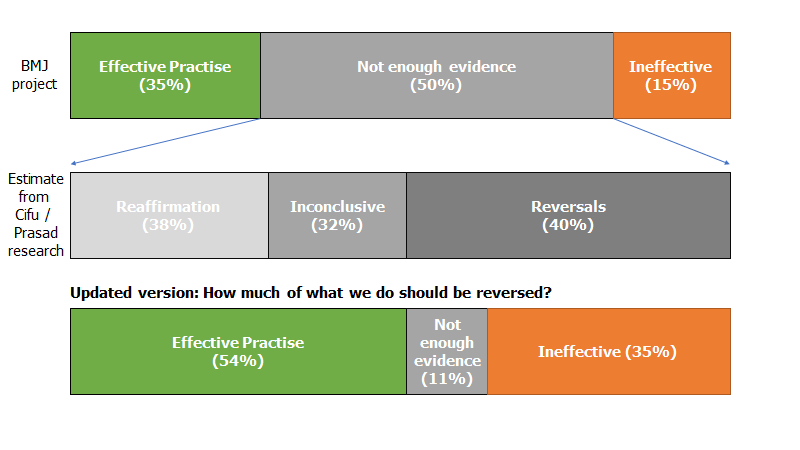
Prasad og Cifu gik ud fra et BMJ projekt hvor man forsøgte at lave en oversigt over problemet. De tog en stikprøve fra “not enough evidence” gruppen, og fandt overstående fordeling (mellemste rektangel fra oven). Nederste rektangel viser den endelige konklusion ifølge Prasad og Cifu: 1/3 af det vi laver er ineffektivt
Hvorfor har vi så ikke allerede tilbagekaldt de 1/3?
One of the lessons of medical reversal is that horses are very difficult to rein in once they are loose
Prasad og Cifu: Medical Reversal
Havde jeg svaret på det, havde jeg ikke behøvet at lave denne blog. Jeg ved dog, at følgende “leaky pipe model” (Diner og Carpenter et al: Graduate Medical Education and Knowledge Translation: Role Models, Information Pipelines, and Practice Change Thresholds) beskriver hvorfor det tager 10-17 år før noget implementeres. Andre kilder er dog endnu mere pessimistiske (SGEM og Lown instutite, Ken milne og Fargas: Will it take 50-100 years to get the right answer for tPA for stroke?)
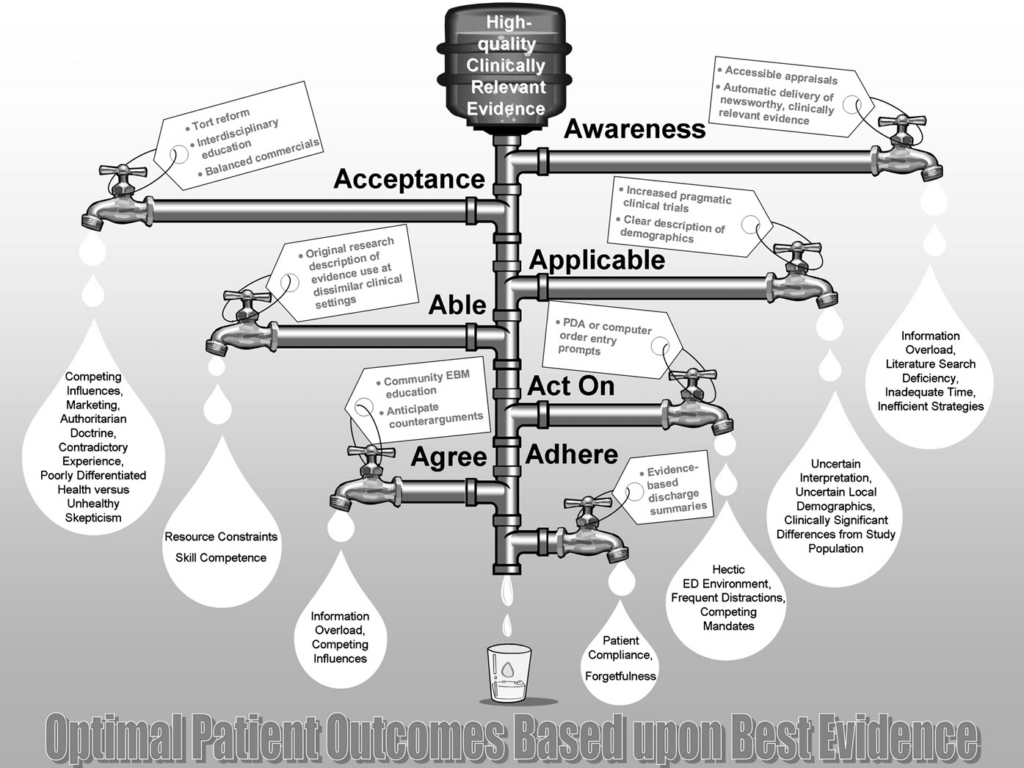
Hvis du undrer dig over 50-100 års pessimismen, så tænk over hvilket ramaskrig det vil være (og er), når det foreslås, at trombolyse studierne bør laves som en ny RCT. Eller hvad med lungeemboli og antikoagulantia? (hør Anand Senthis gennemgang hér eller Prasad). Når noget først er “standard of care”, så bliver det uetisk at randomisere (uanset hvor svag evidens den initiale implementering bygger på). Dette er en af kerne-problemerne!
Ken Milne (SGEM) eksemplificerer dette virkelig godt i eksemplet om trombolyse, og jeg kan anbefale at høre hans podcasts om trombolyse, eller diskussionsartikel med Eddy Lang, eller følgende video (den opsummerer desuden flere af de koncepter jeg har talt om i denne blog indtil videre)
Et særligt grelt eksempel problemer med at ændre noget, når det først er standard of care, kan høres i Emcases Ep 47 om EBM: Før vi behandlede AKS med trombyl og PCI, behandledes det med movikol og streng sengerest da paradigmet på det tidspunkt var, at hjertet ikke måtte belastes. Bernard lown (som I skal høre mere om i del 2), som var en af mændende bag at dette paradigme ændredes, beskriver i sin blog og i sin bog “The Lost Art of Healing”, hvor stor modstand han og Dr Levine blev mødt med, da de ønskede at lave et studie på området. Modstanden overfor vores kendte paradgimer, er ofte ekstrem ud i det absurde:
They accused me of planning to commit crimes not unlike those of the heinous Nazi experimentations in concentration camps. Arriving on the medical ward one morning I was greeted by interns and residents lined up with hands stretched out in a Nazi salute and a “Heil Hitler!” shouted in unison.
Bernard Lown, The Lost art of healing eller blog: A Chair to the Rescue
Historien er ikke bedre af det faktum at Bernard Lown var jødisk flygtning fra Litauen. Bernard Lown kommenterer på den (over)tro vi har på det gældende paradgime med en quote fra den tyske filosof, Scopfenhauer
When a new paradigm takes hold in medicine, its acceptance is extraordinarily rapid. Few acknowledge that they once adhered to a discarded method. This was succinctly captured by the German philosopher Schopenhauer. He maintained that all truth passes through three stages: first, it is ridiculed; second, it is violently opposed; and finally, it is accepted as having always been self‑evident
Bernard Lown, The Lost art of healing eller blog: A Chair to the Rescue
Jeg kan ikke undlade at fortælle, at Dr Lown, som bl.a er kendt for sin nobelsfredspris og opfindelsen af defibrillatoren, altid har været stor kritiker af, at vi i medicin ikke går mere op i den psyko-sociale dimension af patient interaktionen. En stor del af den mortalitet / morbiditets benefit de fandt tilskriver han fraværet af iatrogen skade, som den psykologiske tortur ved streng sengerest- og movikolkur med stor sandsynlighed inducerer.
There was another reason that the detrimental effects of prolonged bed rest were not discovered earlier: the anti-psychology mind-set of medical practitioners. Doctors inadequately appreciate that churning emotions affect every bodily organ. Emotions alter our chemistry, our immune system, our neural traffic; they predispose us to all sorts of illnesses and may even precipitate sudden cardiac death
Bernard Lown, The Lost art of healing eller blog: A Chair to the Rescue
Overstående er med andre ord et fantastisk eksempel, ikke bare på “..but it makes sense physiologically”-problemet (vi tror at vores viden om kroppen er god nok til ikke at lave studier på vores behandlinger – at hjertet eksploderede hvis man rørte sig, gav jo mening, hvis man ikke ved bedre, som vi gør i dag), og problemet med for tidlig implementering af potentiel farlig behandling
Men det var vel dengang…vi er vel blevet klogere?
Covid19 er desværre et godt eksempel på det modsatte, og at for tidlig implementering samt stenhård fokus på gældende paradigme fortsat er standarden. Se bare måden, hvorpå vi har undersøgt effekten af fx hydrochloroquine og oseltamivir…*host*…mener remdesivir (som fortsat promoveres i Sverige af bl.a läkaretidningen, som desuden ikke har fundet det relevant at nævne conflict of interest på en af de promoverende eksperter – sponseret af Gilead, firmaet bag remdesivir – og når påpeget af undertegnet, er denne kommentar blevet censureret). Jeg siger ikke, at nogle studier ikke har været gode (fx RECOVERY studierne), men hele møllen har været enormt ineffektiv og skadelig – ikke mindst pga opportunity cost. Nåja i det mindste har vi ikke været igennem den specifikke problemstilling før….eller?
Professor i akutmedicin, Simon Carley (st Emlyns) har forklaret om “late- og early adapters” og tidligere sat fokus på området. Under C19 så vi noget af det værste (og bedste) forskning overhoved udført, hvilket fik ham og hans team til at skrive følgende meget læsværdige artikel, om et nyt koncept under krisen han kalder Evidence Based Agility (som primært består i en større evne til at adaptere til ny information efterhånden som den kommer, og ikke tage 17 år om at enten implementere eller “medically reverse” en fiasko)
- https://emj.bmj.com/content/37/9/572 (Carley et al, 2020: Evidence-based medicine and COVID-19: what to believe and when to change ) – lyt også gerne til Ken Milne (SGEMs) interview om artiklen, og se Carleys SMACC forelæsning om emne
- Coda Zero forelæsning af simon Carley om dette emne: https://codachange.org/2020/11/11/has-the-covid19-pandemic-been-the-death-of-evidenced-based-medicine-or-the-birth-of-evidenced-based-agility/
Vi har med andre ord bestemt ikke løst dette problem – om noget, virker det til at leve videre i bedste velgående, som bevist under C19. En yderligere kompleksitetsgrad kom Prasad selv med for nyligt, da han stillede spørgsmål ved udløbsdato på den evidens vi allerede har: Should evidence come with an expiration date
Denne maskine er menneskeskab – ingen er onde i systemet, men systemet må og skal laves om, hvis vi vil kunne se vores patienter i øjnene, og informere dem korrekt om, hvad vi egentlig laver.
Distribution og implementering af research
We get the system we deserve – Et system der bør ændres?
Der er en grund til at systemet bør ændres / tweakes: For hvis det ikke var klart allerede, så skal jeg forklare – systemet er sygt:
Som om overstående ikke var nok, så kæmper vi med sundhedssystemer der bliver dyrere og dyrere, intolerabilitet overfor fejl- og usikkerhed (og medfølgende overdiagnostik- og overbehandling), indication creep (igen ofte pga lobby-arbejde fra medicin-industrien) m.m. Et yderst komplext system, ofte forsøgt styret “top-down” med et stort “knowledge-gap” imellem “de der bestemmer” (politikere, administratorer, konsulter etc) og den praktiserende patientnære sundhedsperson (lægen, sygeplejersken, SOSU etc). Et skrækinjagende skandinavisk eksempel (som vi ikke har hørt så meget om i Danmark) er skandalen med “Nya Karolinska” (som der også kommer en blog om engang). Der er skrevet en vel-funderet bog til interesserede på svensk kaldet “Konsulterna” af Anna Gustafsson og Lisa Röstlund (kan man forstå svensk findes de sammenfattet i flere podcasts bl.a denne fra 2020)
Journals skal også tjene penge
Som alle nyheds-medier, har journals deres egne problemer med credibilitet (nogle mere end andre. Dygtige critical appraisers som Casey Parker og Justin Morgenstern plejer at nævne, at NEJM er blandt de mest etisk problematiske. BMJ og JAMA er formentlig i den anden ende af spektret, men fortsat med grundproblemerne). De har behov for at sensationalisere. Hans Rosling (læs fx “Factfullness”), talte bedst om dette, og endda på danks TV:
Richard Smith, tidligere editor for BMJ har sagt “Medical journals are an extension of the marketing arm of drug companies”, og tidligere editor for NEJM, Marcia Angell har sagt følgende, som er rammende ekkoer Hans Roslings holdning om medier generelt:
Let me tell you the dirty secret of medical journals: It is very hard to find enough articles to publish. With a rejection rate of 90% for original research, we were hard pressed to find 10% that were worth publishing. So you end up publishing weak studies because there is so mch bad work out there
Marcia Angell, The Danger Within us (af Jeanne Lanzer), 2017
Og det er de store journals.
Vi (og særligt patienterne) har længe indbildt os med, og undervist medicin studerende i, at behandlinger er dikotomier – ikke spektra og nuancer. Vi har kun ringe forståelse af, hvor stor risk-benefit er på de fleste behandlinger (spoiler alert, den er ikke fantastisk på majoriteten), men det er sjældent noget vi forklarer patienten – særligt i akutte situationer. Hvad er NNT på PCI for STEMI / OMI? Hvad er NNT på Trombolyse for iskæmisk stroke?
- Pereira og Ioannidis et al, 2012: Empirical Evaluation of Very Large Treatment
Effects of Medical Interventions
Vi har troet, at den medicinske videnskab skaber “golden bullets” (alt eller intet behandlinger) eller i det mindste “silver bullets” (behandlinger der er “alt eller intet” – også kaldet “parachutes“). De findes: antibiotika er en silver-bullet for svære infektioner; Defibrilering er en golden-bullet for stødbart hjertestop (se flere herunder)

Og behandlingseffekter behøver ikke være store for at være vigtige – men når det små behandlingseffekter kræver det en velinformeret patient (dvs NNT / NNH etc). Særligt når vi udvider behandlings-indikationer (igen…indication creep) og behandler præ-præ-diabetes som en sygdom. Patienten er nødt til at vide, at de er på vej over i “low-value-care” boldgaden, hvor det ofte var bedst uden en diagnostisk label, og med råd om non-farmakologisk intervention i stedet for en pille.
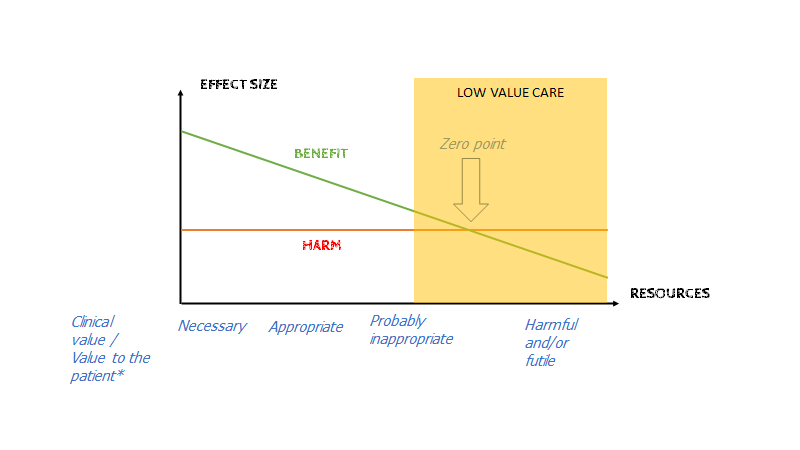
Problemet med at vi tror , at vores behandlinger er golden- eller silver bullets og at vi indfører dem med minimal evidens i (desperat håb / profitable interesseøjemed) er som nævnt herover medical-reversal når de endelig bliver testet. Et modargument der ofte rejses, er “vi behøver ikke teste denne hypotese med RCT, fordi det vil være uetisk – det er jo åbenlyst at det virker”. Meget få ting har så tydelig benefit i moderne medicin, at dette er sandt, Ofte nævnes “men det giver mening fysiologisk”. Dette vil Nasim Taleb og Hume kalde Hybris eller “Fragile” (fordi det bygger på antagelsen om, at vores paradigme / forståelse af fysiologien – ofte ud fra dyrestudier – er sand).
Holder man den vigtige fysiologiske hypotese (…but it makes sense physiologically) som religion, testes (i.e udfordres) disse hypoteser aldrig med RCT’er – fordi det jo giver perfekt mening i vores paradigme (..ligesom igler og blodladning gjorde engang ud fra det paradigme, eller laxantia til AKS). Og farma, som tjener penge på stoffet der nu er godkendt, har ingen interesse i at modbevise det. Det er uetisk at teste en faldskærm! – og om ikke uetisk, så er det medicin-industrielle komplex hurtige til at forklare, at det er meningsløst.
Bottom line:
- Farma er ikke onde, men skal reguleres pga bias og incitamenter
- Forskningskultur må ændres fra “positive resultater” belønnes til “god metodologi” belønnes m.m
- Det meste forskning som produceres nu er enten for dårlig kvalitet eller for biased til at kunne sige noget sikkert om
- Vi har kun 3 måder at få viden på (epistemiologi): fysiologi (rationalisme), og erfaringsbaseret (EBM eller klinisk erfaring). Der findes ulemper ved både det fysiologiske argument (hvis paradigmet eller den fysiologiske forståelse er for simpel – hvilket den ikke sjældent er i komplekse systemer som kroppen), og vel-appliceret EBM (fx behandler ikke individer, men populationer), og særligt apparatet omkring EBM er problematisk (fx forskningskulturen med significance chasing bias m.m). Vi har dog brug for begge dele, for vi har ingen anden måde at få viden på. De tre områder, EBM, erfaring og rationalisme (fysiologi), kan anvendes som hinandens værktøjer for at tjekke om det er rigtigt, det der er fundet. Fx fandt man ud fra studier (Alexander hamilton, 1809) ud af, at blodladning af sepsis patienter var en dårlig idé som ellers var det rationalistiske argument i starten af 1800-tallet (kilde: https://www.youtube.com/watch?v=Fb-2QtCQeqw&t=1803s 37:00). Omvendt er det områder, hvor EBM ikke kan anvendes, hvor vi er nødt til at anvende rationalisme og (det vi tror er) viden om kroppen (tænk bare på din hverdag og spørgsmål indenfor akutte patienter på et akutrum).
Problemet skabes når der ikke er balance mellem argumenterne, og man alene anvender EBM eller alene rationalisme – og særligt, når eksterne interesseorganisationer skaber støj, som er tilfældet diskuteret herover (se Ioannidis og Ben Goldacre). - Medical reversal er et enormt problem som er skabt af overstående – og bygger også på den menneskelige angst: tør vi vente med at anvende noget, som virker lovende, med risikoen for ikke at kunne forske i det sidenhen (fordi nu er er det ude på markedet)
Lad os i del 1C gå videre, og se hvordan research og EBM skaber downstream udfordringer, når det kommer ud i form af guidelines

